2 AI All The Way Down: Infinite Regress and the Future of Quantitative Social Science
Lisa P. Argyle
Purdue University
Ethan C. Busby
Brigham Young University
ethan.busby@byu.edu
Joshua R. Gubler
Brigham Young University
Abstract: Quantitative social science is in a new age, with many exciting possibilities driven by the development and widespread adoption of AI technologies. We articulate some of this promise here, but also point out important concerns for increasing AI integration. We use multiple cases of AI use in the social sciences to discuss important, scientific considerations that researchers should engage with to ensure that AI-empowered social science work contributes to broader scientific knowledge. We propose a version of AI infinite regress to highlight how ungrounded reliance on AI-centered social science production may create a vast body of work of unknown practical value. Ignoring these issues runs the risk of increased AI-enhanced output but decreased understanding and actual scientific and social benefit.
AI usage statement: Generative AI tools were used to format citations and suggest additional sources and references.
A well-known scientist (some say it was Bertrand Russell) once gave a public lecture on astronomy. He described how the earth orbits around the sun and how the sun, in turn, orbits around the center of a vast collection of stars called our galaxy. At the end of the lecture, a little old lady at the back of the room got up and said: “What you have told us is rubbish. The world is really a flat plate supported on the back of a giant tortoise.” The scientist gave a superior smile before replying. “What is the tortoise standing on?” “You’re very clever, young man, very clever,” said the old lady. “But it’s turtles all the way down!” (Hawking 1996)
2.1 Introduction
Artificial Intelligence is reshaping many areas of work, study, and human experience. Quantitative social science is no exception. A Web of Science search for terms related to artificial intelligence1 in social science fields2 suggests the dramatic growth of AI research in the social sciences. As shown in Figure 2.1, the number of social science publications using terms related to artificial intelligence has dramatically increased from fewer than 150 articles in 2014 to more than 8,500 in 2025 (a more than 56-fold increase). As a comparison, growth in social science research on polarization3, another area of intense academic interest in recent decades, has increased far less dramatically since 1990, hitting a high point in 2025 of about 2,300 published articles. This suggests a surging interest in and discussion of AI in social science.
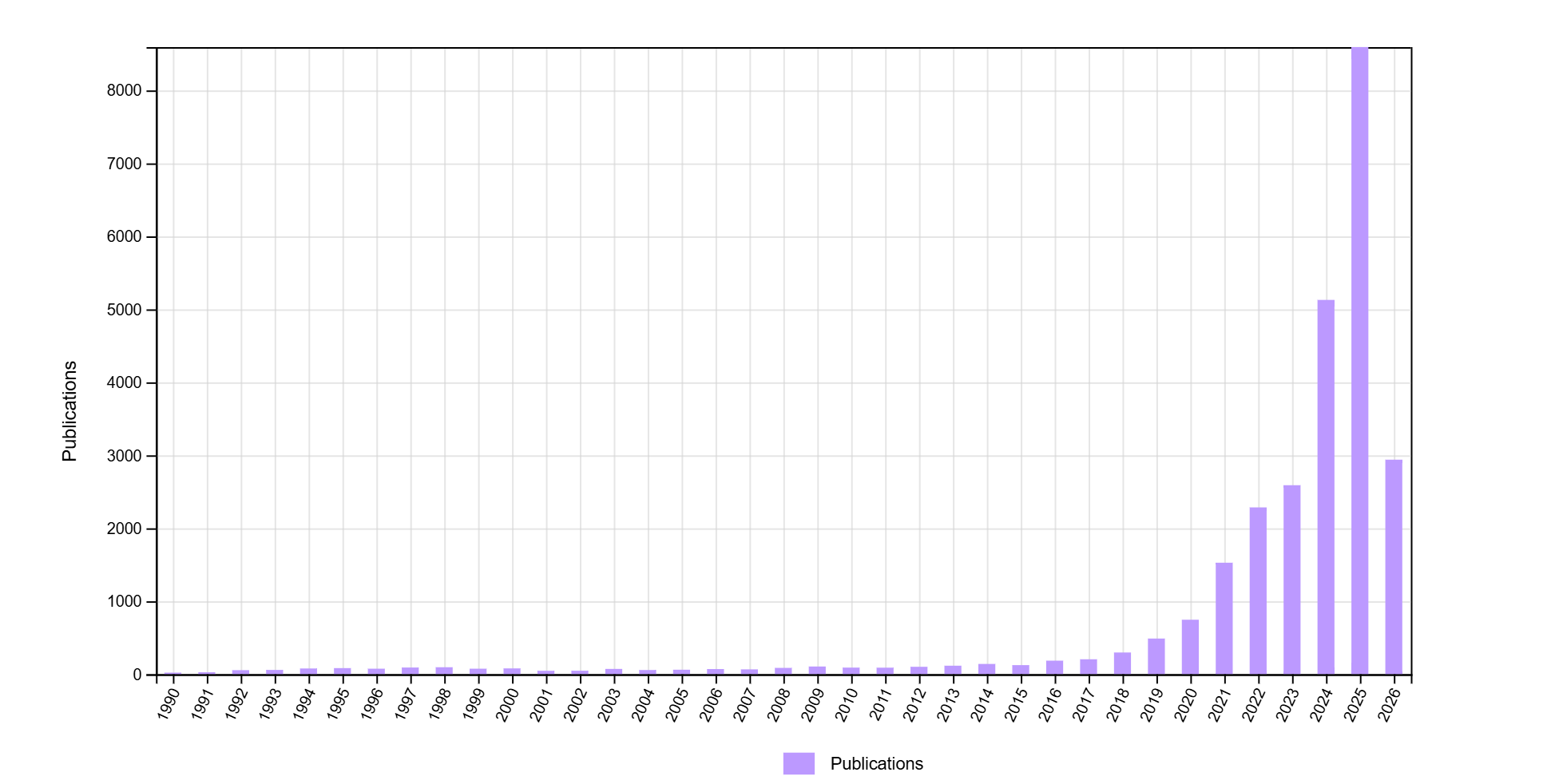
Notably, the impact of AI is not just that social scientists are increasingly interested in AI as a primary substantive focus of their research, but also that the integration of AI now occurs in many non-titular roles (Lyttelton et al. 2026). That is, current AI tools, like the present versions of Anthropic’s Claude Code, Google’s Antigravity, and OpenAI’s Codex, eagerly promise to identify potential questions, develop research designs, canvass relevant academic literature, scour the internet for sources of data (or even simulate synthetic data), run analyses, and write research reports. Importantly, generative AI tools not only create new potential workflows and efficiencies in each of these tasks separately, but they also offer to do so in all of these tasks simultaneously. This creates the possibility of an entirely AI research production pipeline (Hall 2026), with AI increasingly serving as the scientific peer reviewer as well (Russo et al. 2025; Baumann et al. 2026; Kim et al. 2026).
There are both costs and benefits to outsourcing these tasks – and the social scientific endeavor as a whole – to AI agents (Grossmann et al. 2023; Bail 2024; Messeri and Crockett 2024).4 With time, we expect the capabilities of scientific AI tools in these domains will only continue to increase. Because of the vastly lower time and human resources needed for AI to produce content, humans will soon (and may already) be unable to evaluate AI content at the scale in which it can be produced. Thus, the ever-increasing integration of AI tools into science raises profound questions about the role that human social scientists will play in the future.
Drawing on the philosophical problem of infinite regress, we ask: what happens when quantitative social science becomes “AI all the way down”? It is not hard to imagine a world in which AI systems make decisions about questions, identify or simulate data, conduct analysis, and report results, which are evaluated for quality by AI peer reviewers, disseminated to the cloud, and then synthesized and fed into literature reviews of the next AI-directed research project and as training data for future AI models. Thus, quantitative social science faces a potential problem of infinite AI regress, where it rapidly becomes unclear where the fixed point of human reality is on which the AI turtles stand.
In philosophical thinking, problems of infinite regress are not inherently disqualifying for logical argumentation (Nolan 2001; Cameron 2025). We likewise do not claim that researchers can dismiss the scientific system or systems because they may be partially or entirely driven by AI. However, awareness of this kind of infinite regress can point out logical and practical challenges quantitative social scientists should reckon with more openly. To illustrate this, we identify three current, concrete examples of AI-powered quantitative social science and point out deep questions about these uses. Specifically, we discuss how some approaches to AI in social science can limit our collective ability to achieve the core social scientific goal of valid inference. While these problems threaten collective science when replicated at scale, they also pose serious challenges for individual research projects. Thus, we aim to emphasize topics and considerations where every researcher using AI ought to be cautious. Looking across these use cases and specific challenges, our overarching contention is that if we, as a research community, fail to accurately understand the nature of AI tools and do not more intentionally approach them with a scientific mindset, we run the serious risk of misapplying the scientific method and impeding rather than expediting scientific progress.
2.2 Doing Science with Generative AI
We approach this discussion from the vantage of positivist quantitative social scientists, interested in the fundamental goal of using empirical data and observation to make inferences that go beyond one specific set of observed cases or data (King et al. 2021). While we acknowledge this is not a universal orientation, it is perhaps the dominant one in quantitative social science. From this perspective, science seeks to develop explanations rather than simply facilitate the accumulation of disparate and disjointed observations (Lakatos 1970). The goal of the quantitative social scientist, then, is to document observations about the world that provide insight into the plausibility of various theories that explain individual or collective human behaviors, conditions, experiences, and outcomes. Inference is the crucial linking mechanism between the specific empirical observations made by the scientist and the cumulative, collective body of understanding we call scientific knowledge. Valid inferences require alignment between the theory and all aspects of the empirical test, including conceptualization, data generation, and standards of falsifiability. Put another way, we see theory and empirical observation as a way to provide a firm grounding for hypothetical turtles and disrupt a cycle of infinite regress.
We provide three examples of how specific practices and choices by researchers using AI can lead to research outputs that may be difficult to interpret or even misleading in the context of this scientific objective. In this section, we cover standards, conceptualization, and prompting. There are many other elements of science or AI use that could be discussed in a similar way; we aim not to be exhaustive but to give a small set of illustrative examples. We use these cases to illustrate the issues generated by the layering of AI into different (and multiple) parts of the scientific process and how various approaches to these kinds of AI-usages does and does not lead to productive, interpretable knowledge.
2.2.1 Standards for Testing
Scientific inference requires establishing specific standards for testing theories. Theory testing takes a variety of forms, but most often in quantitative social science it relies on the articulation of narrow hypotheses that are the logical empirical implications of a proposed theory, followed by data collection and the use of statistics to contrast hypothesized predictions with a set of null hypotheses. Whether a particular endeavor relies on frequentist statistics, Bayesian methods, some kind of counterfactual thinking, or a different method entirely, scientific work requires the clear statement of testing standards by which a theory can be falsified.
The use of AI in research can dramatically complicate this approach. Generative AI is fundamentally different from prior quantitative tools, such as calculators or software that estimate econometric models. With those kinds of devices, there is some widely-agreed upon standard or benchmark to determine if the task was done correctly (in this case, ensuring the math of various kinds was done correctly). People are also capable of validating performance by these mathematical standards, even if most do not possess the technical knowledge required to do so.
We lack that kind of generally known and accepted evaluation point for generative AI in the social sciences. In some cases, this is because quantitative tools to fully evaluate text (or audio, image, or video) output, while advancing rapidly, are still relatively limited. In other cases, this is because the LLM output is standing in for something that is so complex and multi-dimensional that it may vary in quality depending on what dimensions are prioritized in a given application. Further, the tool itself does not provide any standard of its own to evaluate its performance, nor does it provide any internally-produced warning of when it has failed. There may be some extreme cases of this that may seem like failure-indicators – when, for example, a model refuses to generate some output – but these are largely a result of guard-rails or alignment of the models on the part of their creators rather than an indication that the model would have performed the task poorly according to some applied standard.
To make this more concrete, consider a study that uses LLMs to create realistic conversation partners for human participants. What standard should researchers use to establish that their LLM output is “realistic”? Should researchers compare the complexity of text generated by an LLM to similar statements generated by humans? What conversational features (such as intensity of language, linguistic markers of agreement, negative-positive statements, pauses in speech, etc.) should be comparable across LLM and human speakers? Should researchers query human respondents to determine, in a Turing-esque way, if they can distinguish between LLM and human chat participants? If LLMs are rated differently than humans in comparable roles, what level of divergence is acceptable or indicates a significant issue for a given research study? While we have struggled and worked to justify choices on these types of issues in our individual work (Argyle, Bail, et al. 2023; Argyle, Busby, Gubler, Lyman, et al. 2025), our purpose in listing them is to highlight there is no uniform, community-wide validation standard for even this limited use case, let alone across cases with different objectives.
A similar debate occurs in the rapidly growing literature on silicon sampling, where different scholars come to different conclusions about the suitability of AI-generated proxies of human subjects for public opinion and other kinds of behavioral research. At least one reason for the disagreement between scholars is that different projects often propose different metrics of evaluation (Argyle, Busby, et al. 2023; Santurkar et al. 2023; Bisbee et al. 2024; Kim and Lee 2024; Boelaert et al. 2024). These metrics are not just due to the statistical properties of data, which would be resolvable by appeals to statistical proofs and disciplinary best practices. Instead, they reflect differences in the core conceptualization of what constitutes the central feature of human attitudes and action that needs to be accurately depicted by an AI simulation.
Consider also yet another common task where an AI produces a literature review on some topic for a research paper. What standard should we use to determine if this review has been adequately conducted? This complex task requires understanding of written grammar and tone, conventions of academic disciplines, knowing when a sufficient amount of research has been covered, and an expert evaluation of what literatures are relevant and what the work in those literatures contributes. Human authors assigned the same literature review task would each produce something different from each other and from an analogous AI system, and so a match of specific words or themes generated by human and AI agents is likely to be insufficient. Experts themselves might disagree on whether this task has been sufficiently performed (see the oft-cited demands of “Reviewer 2”). For a human to evaluate whether the relevant academic literature has been comprehensively surveyed requires the human evaluator to have a (nearly) comprehensive understanding of the literature themselves. But often scholars use AI tools in settings where they themselves are not experts, and thus they rely on other non-systematic textual cues to determine the plausibility and reasonableness of an AI summary. To be clear, academics often require these tasks of their human research assistants, but we show a tendency to trust more blindly in AI tools than in our students.
All of the foregoing issues are further compounded by the use of AI agents to evaluate other AI/LLM outputs from these tasks. It is not an uncommon practice to use AI tools as “judges” to evaluate what other AI systems create (Zheng et al. 2024; Krumdick et al. 2026; Yu et al. 2025). This has many benefits, as it can leverage core strengths of LLMs to process unstructured texts, summarize information, and make sense of complicated data; we have used it ourselves in this way for these very reasons (Argyle, Bail, et al. 2023; Lyman et al. 2026). At the same time, this adds another layer of turtles, so to speak, to the issue of standards and evaluation. This kind of AI-evaluation system is subject to the same kinds of validation questions as the systems they are assigned to assess. Can an AI tool, for example, sufficiently evaluate the adequacy of an AI-generated literature review? How would we then evaluate the tool doing the evaluation? And so on, all the way down.
What does this mean about the future and work of quantitative social science? In the short term, we suggest it is critical that researchers using generative AI explicitly describe and defend relevant validation standards for their specific use of an AI tool (Argyle, Busby, Gubler, Hepner, et al. 2025). These justifications require more than just a defense of the statistical properties of a particular metric, but require attention to the sufficiency of one or more standards for the complex and multidimensional task being performed by the AI tool. Empirical validation of output relative to a concrete, pre-determined standard is one way to interject in the cycle of AI regress and determine what the turtles are really standing upon. In the long term, scientific progress will be accelerated by community-wide discussions across research teams to develop some shared or commonly understood standards that can be used across research teams and applications. Lacking these benchmarks will impede the growth of scientific knowledge across the many parts of social science disciplines and make much of the increasing quantity of AI-powered work of uncertain value.
2.2.2 Conceptualization and Measurement
Tests of theories, of all types, require reliable measures derived from useful or well-constructed concepts. As Gerring notes, “…concept formation lies at the heart of all social science endeavors. It is impossible to conduct work without using concepts” (Gerring 1999, 359). Without reliable measures or useful concepts, the results of any particular test will be inconclusive in assessing a particular theory about the world.
This point is not new or restricted to generative AI tools. It is also independently important from the issues raised in the preceding section about validation and standards. However, in an age of AI, there is a significant temptation to offload this conceptual and measurement work to AI with little guidance or direction from human researchers or the scientific community. This raises significant concerns about the murky foundations of research that places these tasks too trustingly in the exclusive (and metaphorical) hands of AI tools.
Consider a researcher who wishes to use a LLM to identify when a politician makes emotional appeals in their public speeches. The notion of what counts as an emotional appeal, how to measure emotions, and which specific emotions to consider is a source of disagreement for scholars who actively work in this space. For example, some focus on a set of discrete emotions (Marcus et al. 2000, 2011; Clifford and Piston 2017; Albertson and Gadarian 2015) while others emphasize more general notions of positive and negative affect (Lodge and Taber 2013). Rather than engaging these debates and trying to learn from them, it is tempting for social scientists to rely on the black-box judgment of an ever confident and helpful AI assistant.
Using AI in this process might take a number of forms, some of which adhere to rigorous scientific standards and others that sidestep them. For example, a researcher could design a prompt for a LLM that includes a detailed explanation of how to conceptualize emotions in this case, what linguistic features correspond to which types of emotion, and develops a detailed measurement metric to validate coding choices. This can be done iteratively (and transparently), through various prompting techniques, in-context learning, fine-tuning, etc. In this example, the researcher assumes the burden of developing, as carefully as possible, the larger conceptual notion of emotions based on existing scientific research and constructs a particular measurement for LLM content that corresponds to the conceptualization. This researcher might further engage in an extensive validation exercise to verify that the concept and measures they attempted to distill into the language model were faithfully executed. This again could take many forms, such as dividing the data into training, testing, and validation sets or through a number of other established text-annotation practices. For this approach, scholars cannot assume transferability across different concepts, and thus every researcher using AI in a similar way would need to engage in this process for every new concept or application to a new data type.
At the other end of the spectrum is a scholar who, in the face of conceptual and measurement disagreements, chooses to simply allow the LLM to resolve these issues for them. Rather than defining emotions or key linguistic features, this researcher simply asks the LLM to indicate when emotional appeals are being used and to report that in whatever way seems best suited to the data at hand. Generally speaking, we would expect the LLM to complete this task (that is, not refuse the request) and come up with a set of measures about emotional appeals that may make good intuitive sense. This has the alluring appeal of efficiency and reduced researcher costs, given that the LLM performs the annotation task quickly and without question or complaint – perhaps unlike a human research assistant or collaborator. However, without a careful application of scientific principles of measurement and conceptualization it is not clear what the results would mean. Imagine that some conclusion about emotional appeals derived from these LLM outputs – their distribution, causes, or effects – challenges an accepted research finding.5 Is this the result of some new knowledge that has been gained or some improvement over existing methods? Or is it because the LLM has performed this task in fundamentally different ways from what other researchers have done or even from what this researcher really intended? Given that there is no way to judge between these possibilities with the data from this pipeline, we suggest that research with this approach has, at best, unknown value.
These are obviously two extreme ends of the spectrum, and much social scientific work falls between these two poles. But we suggest that too much social science work falls nearer the latter approach and too far from the former. To the extent that social scientists push off this kind of step to AI models without active participation, they increase the layers of AI turtles in the scientific process and increase the probability that the value of any result is unknown.
2.2.3 Prompting
All text-based large language models require some text input, or “prompt,” on the basis of which they produce the most probable6 output. Thus, the most direct and effective way a typical user has of providing instructions and guidance to the LLM in completing a task is through prompting. Many approaches to and resources on prompting exist, including those provided by academics (Törnberg 2024; Liu and Shi 2024) and the creators of the LLMs themselves (OpenAI 2026; Google Cloud 2026; Anthropic 2026). Much of this advice can be task and model specific, although some general principles may exist.
It is widely documented that even very small changes to a prompt, including changes such as order or wording that should not change the semantic meaning, can have sizeable impacts on how an LLM performs a task (Zhuo et al. 2024; Atreja et al. 2025; Abraham et al. 2025). Given both the importance and the instability of prompting, how should quantitative social scientists think about prompt development from a scientific perspective? Do researchers need to propose a theoretically grounded prompt, pre-register this, and deploy this prompt without deviation or modification? Should researchers be free to experiment with, modify, and test prompts until they reach some level of performance? Is it preferable to require those who use LLMs to document the development and selection of their prompts along with their other research materials? Does variation in LLM outputs based on semantic rewording represent something acceptable or undesirable? Prompts can be thought of in different ways, from something akin to a statistical test to something more comparable to a survey question. Accordingly, there are a variety of perspectives on this topic, from those comparing various forms of prompt development to p-hacking (Kosch and Feger 2026) with others suggesting different approaches depending on the research use of LLMs in a given setting (Argyle, Busby, Gubler, Hepner, et al. 2025).
To illustrate this further, consider the case of three researchers who wish to use an LLM to generate persuasive messages on different topics to be shown in a dynamic, live way to human respondents. The researchers each carefully craft a prompt using a variety of best practices and substantive expertise. This might include explaining (in the prompt) the particular output style that is needed, the position the message should take, and what persuasive features should be varied in what ways. It could also involve comparing a given prompt to those recently used by other research teams to complete a similar task.
From here, paths diverge depending on each researcher’s orientation to prompting (represented by Researcher One, Researcher Two, and Researcher Three). From a stricter approach, Researcher One would then deploy these initial prompts in their research design as constructed without further tinkering or validation prior to their use. The prompts may be imprecise or have some unexpected issues, but they conform (at least superficially) to a set of pre-determined goals and ideas by the researcher. Taking a moderate approach, Researcher Two might first test the initial prompts with members of their research team and assess if the prompts work equally well on different topics or for respondents with different characteristics. Having gathered these data, they would then introduce a set of moderate changes to the prompt that might result in different prompts in different circumstances or for different kinds of users in the same study. From a more radically flexible orientation, Researcher Three might use the same pre-study tools as Researcher Two but also actively monitor the performance of the prompts in real time and make a series of adjustments on-the-go as the study unfolds to maximize some desired performance on the part of the LLM.
We would expect concerns or objections to each of these approaches for good reasons. Researcher One may have the clearest sense of what they intended with their prompts and most readily conform to quantitative social science standards of pre-registration and transparency. However, they may suffer from poor LLM performance due to a misunderstanding about how LLM interact with prompts. Thus, while they have a transparent research practice, the slippage between what they intend and what the LLM actually does makes it unclear what inferences to draw on the basis of the research exercise. Researcher Three, on the other hand, may have the benefit of being maximally adaptive so that the LLM achieves peak performance, but also (inadvertently) undermine the reliability of any inferences that can be drawn from such a study because the treatment generating process may introduce sources of systematic variability.
Our contention here is not to recommend any particular approach to prompting. It is instead to point out that this is another area where the particular scientific principles at stake can go unaddressed and undefended. Given a particular use of AI, is the most important scientific goal transparency? If so, prompt pre-registration may be critical. On the other hand, if the most important element is internal performance (such as ensuring that some treatment is consistently delivered), more modification and assessment to prompts may be appropriate. Different uses of AI (such as text annotation versus human interaction) may also imply different standards about the reproducibility of LLM outputs with a given prompt.
In the bigger picture, small prompting or training decisions made in non-transparent aspects of the full AI research pipeline may have downstream effects that are impossible to predict, evaluate, or account for. Undetected deviations, quirks, or deficiencies in AI output from one aspect of a project then become the basis for decisions in other aspects of the project. And further, as those projects become a part of the cumulative basis of scientific knowledge and inference, they may exacerbate AI regress, leading to a body of scientific work that is based on countless small deviations from human reality. Notably, while this would be most concerning in a world of fully-automated social science, it can impact individual projects and collective knowledge-building even in systems where researchers are trying to make principled best-practice decisions.
Once again, we would suggest that the scientific method does not imply one, never-changing thing about prompting and prompt engineering. Instead, researchers should carefully think about their research objectives, relevant scientific guidelines and standards in their area of work (that predate or exist more broadly than AI), and make defensible, explicit, and transparent choices given those considerations. Because the best practices may require complex human judgment on the basis of multifaceted and sometimes competing considerations, easy-to-apply rule-based standards of “best practices” may become less applicable. The age of AI quantitative social science may require a higher degree of transparency in more aspects of the research process so that cautious and attentive human researchers can better evaluate the full context of research projects and what they imply for valid inference.
2.3 The Meaning and Future of Science in the AI-Powered World
These examples illustrate some of the issues that can come from the layering of AI into quantitative social science. Importantly, these complexities exist regardless of whether human researchers acknowledge them and even in the face of the efficiency and technical gains from increased AI adoption. A central objective, then, is to make considerations of scientific inference more explicit and more deliberately discussed.
One of our short-term predictions about the impact of new AI technology on quantitative social science is a coming era of increasing efficiencies and outputs. Various AI tools allow academics to pursue projects in faster and more automated ways. We think it likely that this will result in more production of research outputs and expanding capacities at the level of individual researchers. However, it is not clear that the expanding individual capacity of researchers will create a collective improvement in the ability of the scientific community to generate and test parsimonious theories that advance our understanding of the world by allowing us to make valid inferences.
In thinking about these risks, a useful parallel is in the way that AI has shifted the online information space. As others have shown, various AI tools have the capacity to help people become better informed, be persuaded by information and arguments, and reassess their problematic beliefs (Costello et al. 2024; Crabtree et al. 2025; Offer-Westort et al. 2026; Argyle, Busby, Gubler, Lyman, et al. 2025; Velez et al. 2025). In these ways, and many others, AI might be able to improve the current information environment. However, that does not appear to be the case at present. While generative AI has undoubtedly increased the amount of content online, much of it falls into the category of “AI slop,” light entertainment, deepfakes, and misinformation (intentionally or otherwise). Because these tools have not been constrained to follow the principles required to improve the informational ecosystem, they have (in the aggregate) thus far failed to do so. It is increasingly difficult to determine what of the AI-generated content contains real, helpful information and what is either neutrally or maliciously unhelpful.
We contend that the same is possible with respect to quantitative social science in an AI-empowered age. While it is the case that AI tools can produce more things that appear to be scientific research, without careful attention to the principles of good science and the foundations upon which these AI tools stand, we fear these products will add little value to the scientific community and broader society. To the extent that the goal of quantitative social science is to help people better understand individual and social processes in order to make informed decisions and improve social outcomes, producing scientific research using AI at a scale which can only be reasonably processed by AI seems fundamentally at odds with that goal. Slowing that tide will require more than just an appeal to the restraint of individual researchers, but will require the scientific community to establish norms, institutions, and incentives aligned with our collective goals.
On the other hand, we recognize that there are significant opportunities with the increased scale and efficiency of AI-powered research. AI tools with sufficient capacity may eventually make redundant the role of the quantitative social scientist as we currently understand it. However, we view the core scientific principles outlined here as having even more importance in that world, rather than less. The path from the current state of AI tools to that future will require the dedicated and ongoing creativity of the social scientific community, in order to ensure that we have the most appropriate validation tests, meaningful concepts or processes for transparently understanding and adjudicating between competing understandings of the same concept, and best practices for transparent model instruction (through training or prompting). Without making some attempt to look down the stack of turtles, it will not be clear if that tower is leading somewhere helpful, productive, and useful or to an entirely different place. Jumping straight into AI-powered social science without attention to these and other guiding principles of social scientific practice risks losing far more than we are able to gain.
These terms included “artificial intelligence”, “AI”, “language model”, “LLM”, and “generative AI”↩︎
We included the WoS categories of: Anthropology, Behavioral Sciences, Economics, Geography, International Relations, Neurosciences, Political Science, Psychology, Social Sciences, and Sociology↩︎
We included the terms “polarization”, “polarized”, and “political polarization”↩︎
This says nothing of larger debates about the environmental, economic, and social impacts of the development of and reliance on AI technologies.↩︎
This would be equally true of work that supported existing findings.↩︎
Noting that these are no longer simple probability distributions on the basis of training data, but are also a result of further fine-tuning, alignment, reasoning, or optimization processes.↩︎