3 The Science of Quantitative Social Science in an Age of Artificial Intelligence
Lisa P. Argyle, Political Science, Purdue University
Ethan C. Busby, Political Science, Brigham Young University, ethan.busby@byu.edu
Joshua R. Gubler, Political Science, Brigham Young University
Abstract: Quantitative social science is in a new age, with many exciting possibilities and much potential driven by the development of a variety of AI technologies. We articulate some of this promise here but largely offer a cautionary note. We argue here that if social scientists do not come to (1) better understand the nature of generative AI and (2) better apply the elements of science in light of that nature, we may find ourselves overwhelmed by the risks rather than the benefits of AI. AI usage statement: Generative AI tools were used to format citations and suggest additional sources and references.
3.1 Introduction
Artificial Intelligence has and continues to have profound impacts across sectors of society, domains, disciplines, and countries. This statement now likely seems so obviously true that stating it runs the risk of being pass'e. Nonetheless, AI and the cascading changes it brings along with it are reshaping many areas of work, study, and human experience.
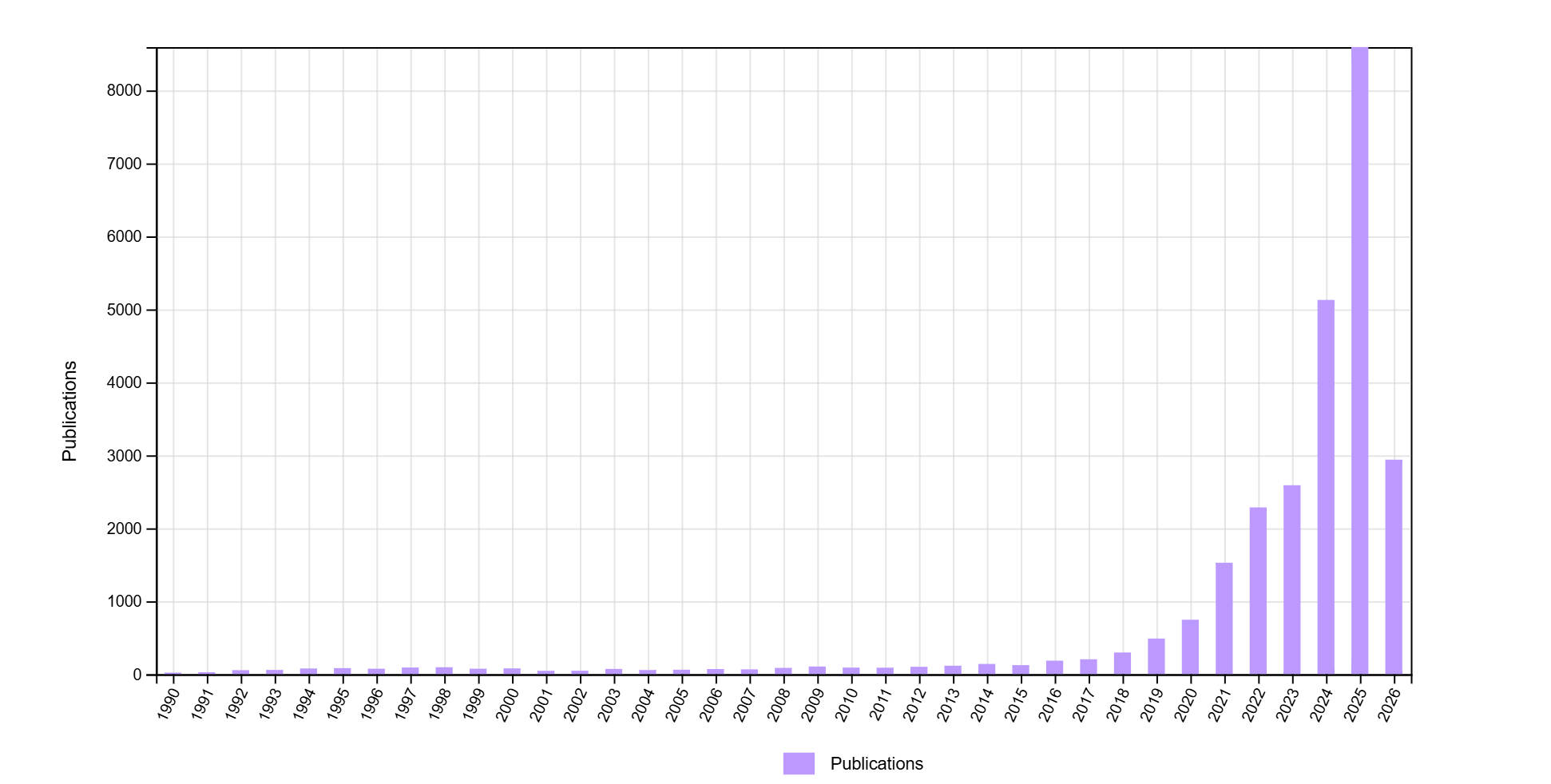
This is definitely true of quantitative social science. A Web of Science search for terms related to artificial intelligence1 across a number of social science fields2 suggests the dramatic growth of AI research in the social sciences in the last 6 years. As shown in Figure 3.1, the number of social science publications using these terms has dramatically increased from fewer than 150 articles in 2014 to more than 8,500 in 2025 (a more than 56 fold increase). As a comparison, growth in social science research on polarization3, another area of intense academic interest in recent decades, has increased far less dramatically since 1990, hitting a high point in 2025 of about 2300 published articles. All of this suggests a surging interest in and discussion of AI in quantitative social science.
The ever-increasing capacities of AI tools raise deep questions about the role that human social scientists will play in the future. Current AI tools, like the present versions of Anthropic’s Claude Code and OpenAI’s Codex, offer to develop research designs, canvass relevant academic literatures, scour the internet for sources of data, run analyses, and write research reports. While these tools have present limits and there are costs and benefits to outsourcing these tasks to AI agents Messeri and Crockett (2024), we expect the abilities of AI tools in these areas will only continue to increase.
In the face of this changing landscape, we think it time for researchers to grapple with a set of difficult questions. Many of these center around a common theme: what do advances in artificial intelligence mean for quantitative social science? What does the human quantitative social scientist contribute in this AI era? Elsewhere, we have argued that generative AI tools are as disruptive and transformative as other crucial technological innovations, like the adoption of the internet in the late 20th century (Argyle, Busby, Gubler, Hepner, et al. 2025). In the face of these disruptions and possibilities, we suggest that it is crucial for quantitative social scientists to return to their roots as scientists and to think deeply about (1) what generative AI is and (2) how to apply the scientific method in an AI-empowered age of research. Our main contention here is that if we, as a research community, fail to accurately understand the nature of AI tools and to approach them with a scientific mindset, we run the serious risk of misapplying the scientific method and impeding rather than encouraging scientific progress.
3.2 The Nature of Generative AI
Science is not just concerned with stimulus - outcome, but with explaining the link between. It seeks to generate inferences that go beyond one specific set of observed cases or data (King, Keohane, and Verba 2021): it is not interested identifying that one variable (X) caused another (Y) in a specific circumstance; it aims to uncover specific conditions and factors that lead us to expect that variable X will typically cause variable Y. Science seeks to develop these kinds of explanations (theory) rather than simply facilitate the accumulation of disparate and disjointed observations (Lakatos 1970).
In the positive social sciences, this orientation leads to a focus on identifying particular individual-level (psychological) and social/institutional mechanisms that are universally shared (for one reason or another: evolution, social construction, etc.). We construct theories of mind, theories of social group formation, and so forth that rest on assumptions of stable/universal processes that, once identified, explain human attitudes and behavior not just in one case, but many. Scholar often call these data-generating processes (DGPs), and conceive of them playing a role like algorithms. They model a knowable, observable process that leads to the outcomes and observations we see in the world around us. Of necessity, we assume that our (biased) observations represent at least a shadow of “true” DGPs and then focus our attention on building models of these DGPs. These are theories. Surveys, participant observation, behavioral measures – all measure elements proposed by these models.
However, what happens to the social scientific method when when its output remains focused on humans, but its input is not human but artificial, where the foregoing assumptions don’t hold? Large Language Models (LLM) generate output that feels like the observations we get from humans, but isn’t generated by the structures underlying human intersubjectivity or by some shared structure or process (DGP) across different models or even instances of the same model. At present, the best LLMs are nests of LLMs and other types of programs, each with different DGPs and purposes. The multitude of DGPs inside these programs are both proprietary and opaque. Instead of being stable, they constantly change in ways unidentifiable to most social scientists using them. Moreover, LLM results are probabilistic, generating outcomes much less certain than typically assumed by the algorithm-like DGPs that constitute most social science theories. LLM outcomes depend heavily on the features of each particular AI, post-training alignment processes, and the nature of the instructions (prompts) used by quantitative social sciences.
To illustrate this difference with a more concrete example, consider that much of social science assumes that human behavior is motivated by some kind of rational self-interest. In other words, the things that people do are driven by the things that benefit them and the methods that people believe will lead to these benefits. There are a number of proposed modifications to this approach (such as assumptions about the amount of information people possess, the conditions under which they behavior irrationally, and so forth), but much of social science assumes a shared DGP – a shared theory about human nature – that applies to humans across locations, times, and contexts.
When used to simulate human data, LLMs have no such consistency across time and space. While there there must be a DGP that leads to a particular LLM output at a specific point in time, this process is neither consistent within the same LLM across points in time nor across different LLMs at the same moment in time. As such, human-like observations from LLM data are fundamentally different than observations derived from humans and should be treated as such. This suggests important limits on the role of LLMs in theory building, and a variety of different considerations when using LLMs in a scientific enterprise than there would be with the use of other tools. To return to our earlier example, while an LLM can be prompted to produce what seem like self-interested human results, those results will vary depending on a host of factors unrelated to the self-interest of humans, and about which we as scientists are often unaware (inside the models) or about which we are not often careful (prompting language choices, model choices, etc.). To our mind, this means that when using LLMs and generative AI to model, mimic, and map human behavior (at an individual, group, or other level), quantitative social scientists must evaluate and publicly justify the value of AI outputs every single time. This is dramatically different from how social scientists otherwise approach research, where they frequently (and sensibly) rely on validation done by others or justifications provided in prior research for use of their tools and approaches.
3.3 Doing Science with Generative AI
We provide two examples of how we suggest this understanding of AI leads to specific practices and choices by researchers that are different from what they might otherwise do, but that are essential for the growth of scientific knowledge. The first of these deals with the standards used in scientific testing and the second with issues of conceptualization and measurement.
3.3.1 Standards for Testing
Science involves establishing specific standards for testing theories. Theory testing takes a variety of forms, but most often it looks something like the articulation of narrow hypotheses in a research study and the use of frequentist statistics to contrast hypothesized predictions with a set of null hypotheses. Whether a particular endeavor relies on frequentist statistics, Bayesian methods, some kind of counterfactual thinking, or a different method entirely, scientific work requires the clear statement of these testing standards.
We suggest that use of AI in research complicates this approach. What should standards be for studies that employ generative AI to make conclusions about or study humans? In this way, generative AI is fundamentally different from older tools, such as a calculator. With those kinds of devices, there is some widely-agreed upon standard or benchmark to determine if the task (in this case, math of various kinds) was done correctly. We lack that kind generally known and accepted evaluation point for generative AI. Further, the tool itself does not provide any standard of its own to evaluate its performance.
What standard, for example, gives evidence that a synthetic representation of public opinion corresponds with human views in a way that is useful or helpful to social science? When does a LLM report accurately how people might behave under a specific set of conditions? While a great deal of computer science work with generative AI relies on benchmark assessments of models (new and old), these benchmarks are not designed with social science tasks in mind.
To make this more specific, consider a study that uses LLMs to create realistic conversation partners for human participants. What standard should researchers use to establish that their LLM output is “realistic”? Should researchers compare the complexity of text generated by an LLM to similar statements generated by humans? What conversational features (such as intensity of language, linguistic markers of agreement, negative-positive statements, pauses in speech, etc.) should be comparable across LLM and human speakers? We face a significant omitted variable bias problem here.
Should researchers query human respondents to determine, in a Turing-esque way, if they can distinguish between the LLM and human chat participants? If LLMs are rated differently than humans in corresponding roles, what level of divergence is acceptable or indicates a significant issue for the research study? While we have struggled to justify choices on these types of issues in our individual work, our purpose in listing them is to highlight there is no uniform, community-wide validation standard for even this limited use case, let alone across cases with different objectives.
In the short term, we suggest it’s critical that researchers using generative AI explicitly describe and defend relevant validation standards for their specific use of an AI tool. Long term, scientific progress will be accelerated by community-wide discussions across research teams to develop some shared or commonly understood standards. Lacking one or both of these things will impede the growth of scientific knowledge across the many parts of social science disciplines. Presently, these kinds of discussions are either only a limited part of published work or relegated to informal discussions between colleagues with no real place in the academic town square.
3.3.2 Conceptualization and Measurement
Tests of theories, of all types, require reliable measures derived from useful or well-constructed concepts. As Gerring notes, “…concept formation lies at the heart of all social science endeavors. It is impossible to conduct work without using concepts” (Gerring 1999, 359). Without reliable measures or useful concepts, the results of any particular test will be of uncertain value in assessing a particular theory about the world.
This point is not new or restricted to generative AI tools. It lies at the heart of the work on conceptualization and the varied empirical approaches to measurement and operationalization. However, in an age of AI, there is a significant temptation to offload this conceptual and measurement work to AI with little guidance or direction from human researchers or the scientific community.
Consider a researcher who wishes to use a LLM to identify when a politician makes emotional appeals in their public speeches. The notion of what counts as an emotional appeal, how to measure emotions, and which specific emotions to consider is a source of disagreement for scholars who work in this space. For example, some focus on a set of discrete emotions (Marcus, Neuman, and MacKuen 2000; Marcus, MacKuen, and Neuman 2011; Clifford and Piston 2017; Albertson and Gadarian 2015) while others emphasize more general notions of positive and negative affect (Lodge and Taber 2013). Rather than engaging these debates, it is tempting for social scientists to offload this conceptual and measurement work onto generative AI.
This might take a number of forms, some of which adhere to the most rigorous scientific standards and others that sidestep them. For example, a researcher could carefully explain how to conceptualize emotions, what linguistic features correspond to which types of emotion, and work to develop a detailed measurement metric to validate coding choices. This can be done iteratively (and transparently), through various prompting techniques, in-context learning, fine-tuning, etc. In this example, the researcher assumes the burden of developing as carefully as possible the larger conceptual notion of emotions based on existing scientific research and constructs a particular measurement for LLM content that corresponds to the conceptualization. This researcher might further engage in an extensive validation exercise to verify that the concept and measures they attempted to distill into the language model were faithfully executed. This again could take many forms, such as dividing the data into training, testing, and validation sets or through a number of other established text-annotation practices. By this model, every researcher using AI in a simlar way would need to engage in this process for every application, as the evaluations from a previous study may have no bearing on a new or different application. This is what we propose.
At the other end of the spectrum is a scholar who, in the face of conceptual and measurement disagreements, choose to simply allow the LLM to resolve these issues for them. Rather than defining emotions or key linguistic features, this researcher simply asks the LLM to indicate when emotional appeals are being used and to report that in whatever way seems best suited to the data at hand. Generally speaking, we expect the LLM to complete this task (that is, not refuse the request) and come up with a set of measures about emotional appeals that make good intuitive sense. This has the alluring appeal of efficiency and reduced researcher costs, given that the LLM performs the conceptual and measurement work. However, in this case, without a careful application of scientific principles of measurement and conceptualization it is not clear what the results mean. If some conclusion about emotional appeals derived from LLM outputs - their distribution, causes, or effects - supports or challenges existing work, is this because there is some new knowledge that has been gained? Or because the way the LLM has performed this task is fundamentally different from either what other researchers have done or even from what this researcher really intended? We suggest that there is no way to judge between these possibilities, giving research with this approach at best, unknown value.
These are obviously two extreme ends of the spectrum, and much social scientific work falls between these two poles. But we suggest that too much social science work falls nearer the latter approach and too far from the former.
These terms included “artificial intelligence”, “AI”, “language model”, “LLM”, and “generative AI”↩︎
We included the WoS categories of: Anthropology, Behavioral Sciences, Economics, Geography, International Relations, Neurosciences, Political Science, Psychology, Social Sciences, and Sociology↩︎
We included the terms “polarization”, “polarized”, and “political polarization”↩︎