flowchart LR tools["AI Tools"] errors["New Sources<br/>of Error"] multi["Cheap Multiverse<br/>Analysis"] mistakes["AI Error"] control["New Source<br/>of Agency Loss"] influence["AI Influence over<br/>Research Direction"] tools --> errors errors --> multi errors --> mistakes tools --> control control --> influence classDef box fill:#f2f2f2,stroke:#555555,stroke-width:1px,color:#111111; class tools,errors,multi,mistakes,control,influence box;
17 With Great Powers: A Practical Guide to Agentic AI for Social Science Research
Simone Paci, Stanford University, spaci@stanford.edu
Abstract: Research is undergoing a revolution. Agentic AI over the past year has drastically changed many social scientists’ routines. Yet adoption has outpaced the building of shared best practices and standards, while uneven uptake threatens to introduce new sources of inequalities. This chapter offers a practical guide to catch up to speed as well as a template of effective and responsible use. It parses through the minimum vocabulary for agentic-AI literacy, builds a layered workflow that moves from tool choice through prompt, context, and harness engineering into agent management across the research process, and proposes two core governance principles. The first is researcher control, which aims at maintaining human ownership of every substantive decision; the second is radical transparency, which expands the replication package to include the inputs, throughputs, and outputs of the AI-assisted process. These principles are implementable today using the same infrastructure the paper recommends, and implementing them is the precondition for trust in agentic research workflows.
AI usage statement:
17.1 Introduction
In the space of a few months, a growing share of social scientists have restructured the day-to-day of their work around agentic AI. Recent surveys put researcher adoption of AI tools at 84% (Wiley 2025; Oxford University Press 2024); in parallel, AI-tagged publications in the natural, physical, and life sciences are growing at 26-28% year over year (Stanford Institute for Human-Centered Artificial Intelligence 2026; Arroyo-Machado et al. 2025). The frontier is wider still. Agentic pipelines now run routine empirical work end to end, from data cleaning through heterogeneous-treatment sweeps to publication-ready tables (Pepinsky 2026; Shah et al. 2026), and platforms built around agent orchestration are beginning to automate portions of the research process itself, from question formulation through analysis (Hall 2026). Yet, uptake has outrun understanding. The problem is epistemic: when an agent drafts, runs, or interprets papers, the ordinary anchors of authorship and replicability no longer sit where long assumed by the research community.
Against a growing body of work that frames AI’s implications for social science in programmatic or speculative terms (Grossmann et al. 2023; Korinek 2023; Lu et al. 2026), this paper takes the most concrete approach available: a working manual based on practical and feasible recommendations. I begin with the basic vocabulary a researcher needs to reason about the agentic landscape. In turn, I propose a set of best practices for effective AI deployment: a layered workflow that runs from tool choice through prompt, context, and harness engineering into agent-level management. Around this workflow, I advance an automated and thorough system of input, throughput, and output reporting that pushes the boundaries of current replication standards. In its entirety, the approach is meant to be highly feasible and low-friction, helping level the playing field and begin already-long-overdue community-wide conversations about the future of research.
Running through both the workflow and the governance proposals are two principles that I argue should govern AI adoption in research: researcher control and radical transparency. The first holds that every substantive decision in a project, from theorizing to empirical design through interpretation and line-editing, must remain with the researcher. We may outsource execution, but not at the cost of ownership and judgment. This principle extends the rule-following boundary sketched by Pepinsky (2026) and resonates with normative work on meaningful human oversight (Davidovic 2023; Siebert et al. 2023). The second holds that the burden of transparency and replication has shifted: releasing data and code is no longer sufficient, and a credible replication package must extend to the inputs, throughputs, and outputs of the AI-assisted process itself. This repositions older open-science arguments for the agentic era (Spirling 2023; Barrie, Palmer, et al. 2025) and aligns with current reporting-standards and integrity-infrastructure work (American Economic Association 2026; American Political Science Review 2026; Spector-Bagdady 2025).
The chapter is organized around two threats this methodological shock introduces, and the two responses they call for Figure 17.1. Like every prior methodological revolution, agentic AI brings new sources of error. Cheap, agent-driven specification searches risk the same forking-paths and multiverse problems that have long shadowed flexible analysis under freer compute (Simmons et al. 2011; Gelman and Loken 2013; Steegen et al. 2016), alongside model-specific failure modes documented in Section 17.2.1. What is new is that the tool also exercises agency in the research process, drafting, executing, and deciding alongside the researcher. Recent capability evaluations suggest frontier models are themselves tilting toward decision-loaded tasks, with task preferences increasingly correlated with difficulty and, more recently, agency (Anthropic 2026). The familiar threat of error in execution motivates the practical workflow of Section 17.3: best practices that catch new failure modes before they enter the record. The novel threat of agency loss, AI influencing the direction of research and not just its error rate, motivates the governance proposals of Section 17.4: shared norms that keep substantive decisions with the researcher and the AI-assisted process auditable by the field.
17.2 The AI Vocabulary
Using AI effectively starts with being able to define the tools being used. Three years of agentic AI have moved the binding constraint on effective use outward through three stages: prompt, context, harness (Figure 17.2). The 2022–2023 era of the public arrival of ChatGPT was dominated by prompt engineering, the craft of writing the instruction well enough that the model would do the task. By 2024–2025, as context windows grew, context engineering, the curation of what the model can see in a given session, became what separated a useful session from a failed one. The 2025–2026 frontier is harness engineering: the design of tools, skills, permissions, and control loops available to the model before any single prompt is written. Each frontier has subsumed rather than replaced the prior one, so a researcher today must work across all three. The rest of this section installs the minimum vocabulary the workflow in Section 17.3 will assume, organized into two layers: the tools themselves, and the engineering layers that require careful researcher intervention. Table 17.1 summarizes and exemplifies the key concepts.
flowchart LR prompt["**Prompt**<br/>2022-2023"] context["**Context**<br/>2024-2025"] harness["**Harness**<br/>2025-2026"] prompt --> context context --> harness classDef era fill:#f2f2f2,stroke:#555555,stroke-width:1px,color:#111111; class prompt,context,harness era;
17.2.1 Fundamentals
The obvious starting point is generative AI. Generative models produce text, code, and images from a prompt, and occupy a narrow slice of the wider AI field, which also houses predictive modeling, from basic OLS to classical machine learning. The practical shift in early 2026 consists of agentic generative AI: models wired into an environment that lets them call tools, read and write files, execute code, and loop until a task is done. Chat-based GenAI is limited: it produces text in response to user input1. By contrast, agentic GenAI has, as the name suggests, agency: it can take actions, observe the outcome, and react to it iteratively. Keeping the underlying GenAI model equal, this shift unlocks a myriad of powerful applications.
A session with any such system is a model-instance with a bounded context window. The context window includes all input, throughput, and output ingested and produced by the model. Performance is not uniform across that window: as context fills, the model becomes less reliable, and long-running tasks therefore require either compaction (summarizing earlier turns into a condensed record) or a planned restart. Researchers who ignore this constraint discover it through drifted outputs and silent errors deep in a session. The immediate implication is that complex work is best split across multiple instances rather than crammed into one. One approach consists of agent swarms: a parent agent dispatches scoped tasks to child instances with fresh context and then integrates the results.
Much attention has been paid to model mistakes. I suggest structuring our thinking around two different typologies. “Hallucinations” can be thought of as false-positive errors: a citation that does not exist, a variable that was not in the dataset, a fact that was never in the source (Pepinsky 2026; Abdurahman et al. 2025). The most public early case in research-adjacent settings was Mata v. Avianca (S.D.N.Y. 2023), in which a federal filing cited six fabricated court decisions produced by a chat-based model and not verified before submission. These errors are conspicuous, but relatively easier to deal with: one only needs to check the work. However, a second failure mode is also present and possibly harder to deal with: false-negative errors. This category includes all possible right research actions that were not taken by the agent: information never surfaced from a source document, a falsification check never included (Ashwin et al. 2025; Halterman and Keith 2026; Baumann et al. 2025). This second mode is harder to catch and arguably more dangerous in research contexts: what is wrong is what is absent. Again, the bad news is also good news: researchers still need to “do the work” and ensure that the agent has exhausted all avenues of correct research procedures.
| Concept | Definition | Example |
|---|---|---|
| Fundamentals | ||
| Generative AI (GenAI) | Models that produce text, code, or images from a prompt. A narrow slice of the wider AI umbrella, which also includes predictive and classical ML. | Drafting a literature summary from a collection of PDFs. |
| Agentic AI | A GenAI model wired into an environment that lets it call tools, read and write files, execute code, and loop until a task is done. | Accessing a folder with a dataset, writing code to conduct a falsification check, and, if passed, running an analysis and producing a LaTeX table. |
| Subagent / agent swarm | A parent agent spawns child instances with scoped tasks and fresh context, then integrates their outputs. | A research-lead agent dispatching parallel literature review subagents, one per research topic. |
| AI Failure Modes | Hallucinations or false positives: confident but fabricated output. False negatives: correct procedure never implemented. | Citing a paper that does not exist; not considering an alternative interpretation of a result. |
| Engineering layers | ||
| Prompt engineering | Crafting the instruction given to a model for a single task. | Specifying role, task, format, and worked examples for a text classification job. |
| Context engineering | Curating what the model can see: which files, prior turns, reference documents, and scratch space are visible at any moment. | A project folder with README, roadmap, background notes, and archive of prior research output. |
| Harness engineering | Designing the environment around the model: tools, skills, permissions, and control loops. | Configuring allowed shell commands and available skills. |
| Skill | A text file encoding the researcher’s preferred method for a recurring task. | A lit-review-protocol skill standardizing how every literature search is run and logged. |
| Orchestration | The researcher’s design for how tasks are split and routed across instances, subagents, and skills over a project. | Exploring measurement strategies for a given variable given a dataset: the lead agent manages the procedure while subagents perform analyses for each candidate variable. |
17.2.2 Key Components
Three engineering layers carry the customization work introduced in Section 17.2. Prompt engineering crafts the instruction for a single task. Context engineering curates what the model can see across a session, including reference documents, prior output, and project-specific diagnostics. Harness engineering configures the runtime itself: the tools the agent may call, the permissions it holds, and the control loops it executes. The three remain in active use today, and the workflow of Section 17.3 touches each in turn.
Inside the harness layer, two objects do most of the customization work and deserve separate names. A skill is a reusable, named procedure that an agent can invoke on demand, a short playbook encoding the researcher’s preferred method for a recurring task. Orchestration is the researcher’s overall design for how tasks are broken across instances, subagents, and skills over the course of a project. Together they are the layer at which a generic model becomes a particular researcher’s collaborator, and where most of the practical leverage now sits.
As a useful metaphor, imagine an extremely capable research assistant. Given unclear instructions, blindfolded, and armed with nothing but pen and paper, that RA accomplishes little. Equipped with a clear to-do list, a high-powered laptop, and a curated library of methods texts and prior work, the same person becomes a serious collaborator. Agents are no different. They need scaffolding as precise as the researcher can provide, a task that the rest of this chapter takes up.
17.3 Best Practices: How to Deploy Agentic AI Effectively
The setup stack is five layers deep, and each layer conditions the ones below it (Figure 17.3). Tool choice determines which harnesses can exist on top; the harness determines which skills and tools the agent can reach; context engineering determines what that agent can see inside a given project; the prompt determines what the agent does with what it sees; and agent management determines how all of this gets reviewed and integrated across the research process.
flowchart TB tool["1 Tool choice"] harness["2 Harness engineering"] context["3 Context engineering"] prompt["4 Prompt engineering"] agent["5 Agent management"] tool --> harness harness --> context context --> prompt prompt --> agent classDef layer fill:#f2f2f2,stroke:#555555,stroke-width:1px,color:#111111; class tool,harness,context,prompt,agent layer;
17.3.1 Choice of Toolset
The first researcher choice concerns which GenAI model and which IDE to adopt. The current landscape offers several viable research harnesses, including Claude Code, Codex, Antigravity, and various IDE plug-ins for VS Code and terminal environments.2 Behind those harnesses sit at least three frontier providers in active competition, and the capability frontier has shifted several times in the last year alone (Stanford Institute for Human-Centered Artificial Intelligence 2026), with different models leading on different tasks rather than dominating uniformly (Thomas et al. 2026). Committing a research workflow to a single provider is therefore fragile, and the more durable choice is to build practices that survive a model swap.
A second, less visible choice sits alongside the first. Closed-weights models remain at or near the frontier on most benchmarks, with open-weights models trailing by a modest margin (Stanford Institute for Human-Centered Artificial Intelligence 2026). The gap narrows once replicability enters the picture. As Spirling and others have argued, research that leans on a commercial closed-weights model is effectively unreplicable once the vendor updates or retires that model (Chen et al. 2024; Barrie, Palaiologou, et al. 2025); no amount of careful prompt logging recovers what the vendor has removed (Spirling 2023, 2026; Barrie, Palmer, et al. 2025; Palmer et al. 2024). Open-weights models can be versioned, archived, and rerun. For any result meant to travel beyond proof-of-concept, that property is not a luxury.
17.3.2 Harness Engineering
The first set of choices about harness engineering concerns security. Agentic AI must be granted access to specific environments and permissions to perform specific actions. At one end of the spectrum, an agent could roam the entirety of a machine and perform any action a regular user could. This amount of freedom carries substantial risks (Korinek 2023): an agent could decide to delete years’ worth of work to make room for a large dataset needed to perform an analysis. On the other hand, the model could be quarantined to a sandbox and given minimal permissions. The cost here becomes effectiveness and independence, with the researcher needing to approve every action. A larger discussion of security, beyond the scope of this chapter, involves questions of alignment and models’ increasing ability to circumvent restrictions (Stanford Institute for Human-Centered Artificial Intelligence 2026).
The central artifact inside a harness is the skill library. Through skills, researchers can routinely impose their preferred approach on agents’ behavior. Researchers should think of skills as transcending a specific task or project. Skills are reusable assets and should be centralized and managed across all AI-assisted projects (Stuhler et al. 2025). In practice, researchers should create a single, persistent repository of all their skills, so that agents can follow standard procedures for any given task. The goal of a personalized skill library should be understood as a long-term buildup. My practical advice is that each project should offer the opportunity to either create new skills or review old skills.
Skill-crafting itself should follow a set procedure that combines two types of inputs: external sources and researchers’ own knowledge (Abdurahman et al. 2025; Davidson and Karell 2025). External sources include relevant literature, such as methods papers and authoritative template examples. Internal sources include samples of the researcher’s past work and a self-interview to elicit the researcher’s idiosyncratic preferences and practical tacit knowledge. Figure 17.4 illustrates this proposed approach, while the online appendix offers a template skill-building skill that researchers can use as a starting point for their own libraries.

Alongside clear access to a well-stocked skills library, a harness should include clear orchestration patterns. These are higher-level instructions on how to structure general workflows: complex processes into discrete steps, how to call the correct skills, how to engage the user throughout the process. The building of these documents, which are encoded in text files much like skills, can proceed following the skill-building system outlined above, but should rely on insights on the researcher’s work routines rather than their approach to any given specific task.
Skills and orchestration files do not exhaust the frontier of harness design. A growing body of practice extends agentic setup into what could be called an agentic operating system, a layered architecture in which the harness loads more than tools and skills. Personas are named role configurations the agent adopts, such as senior researcher, line editor, or code reviewer. Identities are persistent profiles encoding the user’s role, preferences, and routines, loaded automatically at session start. Memories are durable repositories of learned context that survive a single session and accumulate over time. Security officers are specialized review subagents that audit other agents’ actions before they touch sensitive artifacts. Together these turn a harness from a per-project setup into a personal operating layer that travels with the researcher across projects. They are the frontier of AI agent setup, currently being explored by tool builders and a small number of practitioners. They are also beyond the scope of this chapter, and not required to implement the workflow recommendations below: the skill library and orchestration files described above suffice for effective and responsible research practice today.
17.3.3 Context Engineering
Once the harness is in place, the following setup step consists of what the agent should see. Context engineering treats the project as a sandbox repository: a single folder that carries all the relevant knowledge for the project, including background concepts, literature, data, scripts, and feedback. The user should also keep their work inside this folder, as if they were sharing it with a research assistant. Any new model instance that begins inside such a folder inherits the project’s full state, improving consistency, effectiveness, and unlocking transparency.
The first type of context engineering aims at making the context easy to navigate for agents through project-specific orchestration files. A well-structured README should state the purpose of the project, the structure of the folder, and any project-specific rules of engagement. A well-maintained implementation roadmap should function as a living to-do list and point of entry for any new model instance starting to work on the project – making spinning a new agent as simple as asking “what’s next?”. Finally, clear instructions should cover routine cleanups through a system of archive subfolders that absorb obsolete material rather than letting it accumulate. These keep the repository legible to any agent instance that enters it, including across long projects in which the researcher’s own memory has faded.
The second context-engineering goal deals with transparency. Every major asset in the folder should be recorded in an asset registry that flags it as human, agent, or mixed, along with a verification status ranging from not-verified through partially-verified to human-verified (Abdurahman et al. 2025; Holst et al. 2025). Part of the project orchestration, implementable through the README file, should instruct agents to log every non-trivial session in an interaction log that records date, researcher input, agent output, and model metadata (American Economic Association 2026; American Political Science Review 2026; Barrie, Palmer, et al. 2025). An emerging line of work on cryptographic authentication of research artifacts suggests these logs could eventually carry stronger guarantees (Gordon et al. 2025), but even the simpler CSV-based version already delivers a reconstructible record of the AI’s role.
Figure 17.5 shows a sample directory tree with its supporting workflows. Such complex context scaffold may seem like a burdensome request of researchers. However, a project-setup skill can implement all of the above at startup, with minimal researcher intervention3. The same appendix also ships a structured literature-review protocol that extends the verification discipline to individual sources, governing how deep-research output is validated, deduped, and filed into the project’s bibliography and classification table. I wrote this chapter following this system and provide the full replication package as a template example. The normative case for treating these mechanisms as part of the replication package is developed in Section 17.4.2.
project/
README.md
implementation-roadmap.md
asset-registry.csv
interaction-log.csv
background/
literature/
concepts/
feedback/
archive/
drafts/
data/
figures/
tables/
scripts/
appendix/
Supporting workflows
| Verification flags | not-verified, partially-verified, human-verified |
| Provenance flags | human, agent, or mixed |
| Interaction log | date, input, output, model metadata |
| Archive pattern | obsolete files move to archive/ |
| Project-setup skill | scaffolds this structure in one invocation |
Beyond the static structure of the folder, the daily use of agentic AI inside this scaffold imposes its own discipline. Every model session runs against a finite context window. Once that window saturates, the model becomes less reliable: earlier instructions slip, constraints drop, and unrelated tasks loaded into the same session start to bleed into one another. The practical discipline is to treat each model instance as cheap and replaceable. Persistent knowledge lives in the project folder, not in the chat. A new session starts from a clean slate, pulls only what the current task requires, and exits before saturation. Figure 17.6 sketches the contrast schematically: a single saturated instance accumulating unrelated active work and compacted history on the left, a fresh task-scoped instance drawing on the structured stack of skills, persona, identity, and memories on the right.
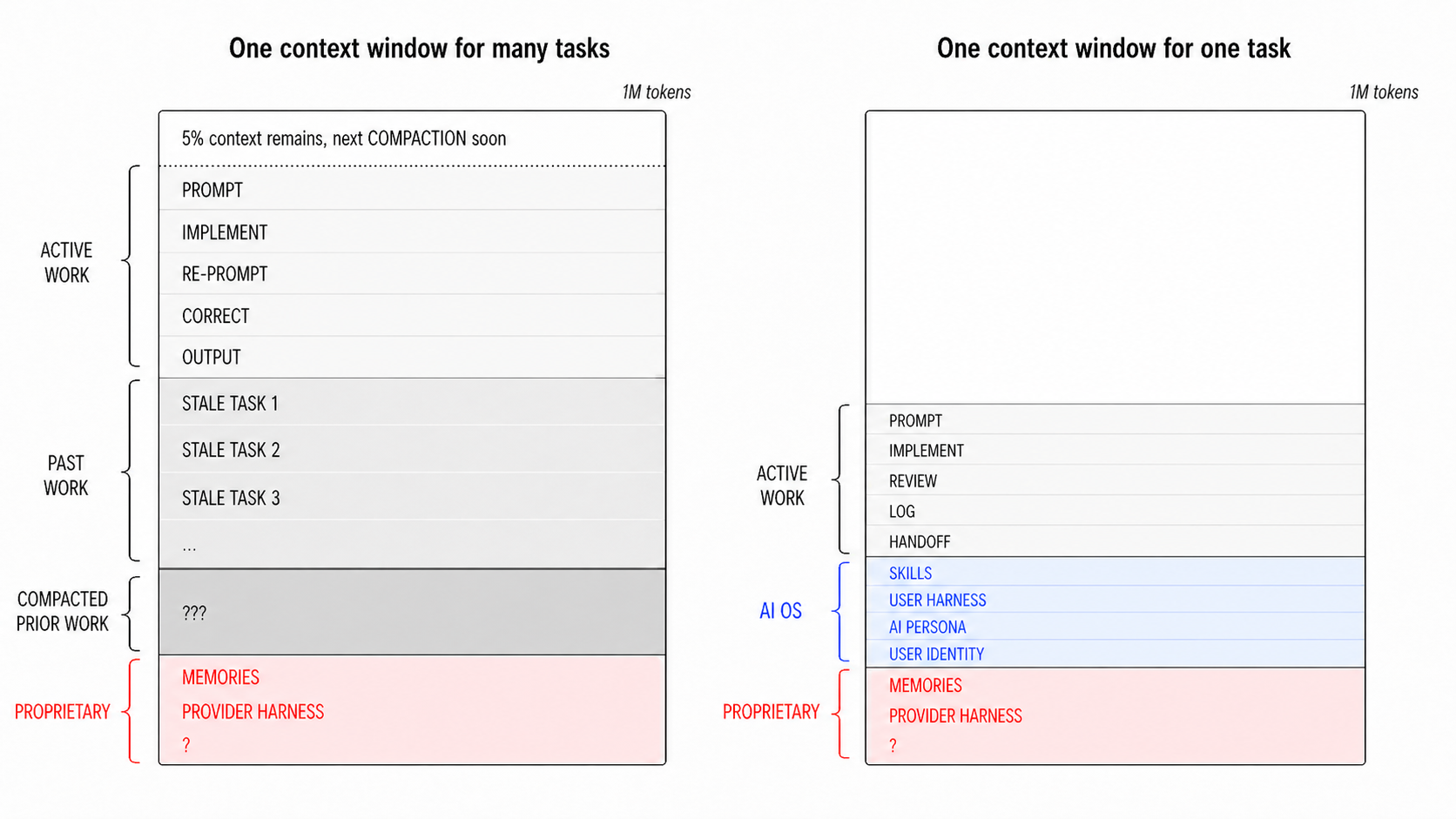
17.3.4 Prompt Engineering
Across specific tasks, the burden on prompt engineering is, at least in part, inversely proportional to the quality of the harness and task-related skills (Stuhler et al. 2025). However, good prompting remains the bedrock of research intent and thus a necessary lever. Prompts, especially large, task-defining ones, provide the goals and focus that agents anchor their work on, within the constraints and guidelines set by the higher-level engineering steps. Managing sessions through prompts – that is “chatting with the agent” – is how the researcher steers the ship and ensures a quality research output.
Instructions should be as precise as possible and might even be construed as the most substantive part of the researcher’s work in its interactions with agentic AI. Agents will fill whatever gaps in the goals or methods stated by the user, and the model’s decisions will be shaped by priors the researcher cannot easily audit (Barrie, Palaiologou, et al. 2025; Baumann et al. 2025; Carlson and Burbano 2026). A prompt that does not specify how a task should be done is a prompt that delegates method to the model (Simmons et al. 2011; Gelman and Loken 2013; Steegen et al. 2016). A good plan is goal-oriented and articulated iteratively with the agent before the agent begins executing. Subplans for each major stage are usually worth the time they take to write, because they replace a long and drifting session with a sequence of shorter, more controllable and accountable ones.
Concretely, researchers can refine their initial prompt through self-interview conducted collaboratively with the agent, akin to the skill-building process. The initial step could be as easy as stating “I need to do X, let’s design a detailed plan for this. Ask me questions about each aspect of X that I should provide instructions for.” My recommendation would be to start with more substantial instructions, as a purely agent-directed self-interview relies on the agent’s understanding of what important components of the task are. Section 17.6 works through a survey-questionnaire example end to end.
A final golden rule here is one instance for one task. Long-running sessions that mix unrelated work decrease agent effectiveness by accumulating context drift, cross-contaminating reasoning, and in turn make control harder. Researchers should always start a fresh session before switching to a new task.
17.3.5 Agent Management across the Research Process
Beyond the setup and best practices above, agentic AI integration requires a sequence of decisions made at every stage of the research process. The first, obvious question pertains to when to deploy agents. Figure 17.7 sketches how all research stages may offer candidate applications for delegation to AI agents. As a general principle, grounded both in questions of effectiveness and control, the researcher should weigh the balance between procedural and substantive nature of the task, understanding these aspects as not mutually exclusive and only partially inversely proportional to each other (Pepinsky 2026; Halterman and Keith 2026; Ashwin et al. 2025). Agents will be strong contenders for tasks that can be performed by following a simple checklist, say making the TikZ package produce Figure 17.4. On the other hand, whenever decisions are substantive, say the structure and content of said figure, agents quickly become more unreliable options.
flowchart LR q["**Question**<br/><br/>scope literatures<br/>surface adjacent work<br/>stress-test framings"] t["**Theory**<br/><br/>trace implications of assumptions<br/>generate derivations<br/>catch inconsistencies"] e["**Empirics**<br/><br/>implement pipelines<br/>run specification sweeps<br/>produce tables and figures"] w["**Writing**<br/><br/>draft, edit, compress<br/>convert across formats<br/>prepare slides"] q --> t t --> e e --> w classDef stage fill:#eeeeee,stroke:#555555,stroke-width:1px,color:#111111; class q,t,e,w stage;
The second management aspect concerns monitoring and verification of AI output. I suggest three layers to this mandate. The first is dual chain-of-thought and final output review: current GenAI systems display the intermediate steps that the agent goes through as they work on a task. Parsing through the agent’s reasoning may flag mistakes and drift between the researcher’s intent and the agent’s final work (Amershi et al. 2019; Tankelevitch et al. 2024). The second involves formulating as many secondary validation checks as possible, such as testing the internal coherence of the output (Abdurahman et al. 2025). The third step is implementing as much of the above through a team of specialized review agents, equipped with skills developed for performing smoke tests of specific task categories (Schmidgall et al. 2025; Lu et al. 2026).
Across these review layers, a common four-step loop organizes how an individual task runs end-to-end. The researcher , typically through the prompt-level interview of Section 17.3.4, then has the agent the plan, often as a composition of skills rather than a single call. The output is then through deterministic checks, not the agent’s self-report. The session closes with a entry in the interaction record. That log entry functions as the seam between sessions: it tells the next instance, and the future reviewer, what the prior agent did and what the researcher signed off on. Repeated across every non-trivial session, the plan-execute-validate-log loop is the operational shape of researcher control inside the workflow.
17.4 Shared Norms: How to Deploy Agentic AI Responsibly
The workflow of Section 17.3 answers a question of effectiveness: how to use AI agents well, given current frontier capabilities. A second question, distinct and equally pressing, concerns responsibility: where to draw the line between the work the agent may do and the decisions the researcher must retain, and how to make the AI-assisted process visible to the rest of the field. The two principles introduced in Section 18.1, researcher control and radical transparency, do that work. This section develops their operational form.
17.4.1 Researcher Control: Procedural vs. Substantive Tasks
The first principle holds that every substantive decision in a project remains with the researcher. Execution may be delegated; ownership and judgment may not. The principle has an operational form, a single question to ask before delegating any task: is the work procedural or substantive? Procedural tasks are rote, the same steps repeated across projects, by many people, with a checkable target. Substantive tasks rely on knowledge that is idiosyncratic to the project: the question, the data, the priors, the interpretation. Agents excel at the former because they have seen the pattern many times and can rely on skills for procedural guidance at scale from the researcher. They fail at the latter because, with no idiosyncratic knowledge to retrieve, they fill the gap with plausible-sounding fabrication (Ashwin et al. 2025; Halterman and Keith 2026; Baumann et al. 2025).
The two ends of the spectrum are easy. Coding a specified estimation pipeline, formatting tables and figures from results, converting between data or document formats, drafting boilerplate sections, compiling references on a keyword: these are procedural tasks where delegation is safe and the gain in researcher time is substantial. Choosing a research question, selecting which assumptions to make, choosing an identification strategy, interpreting coefficient estimates, deciding the central claim: these are substantive tasks where delegation hollows the project out and where the researcher’s domain knowledge strictly dominates a model default.
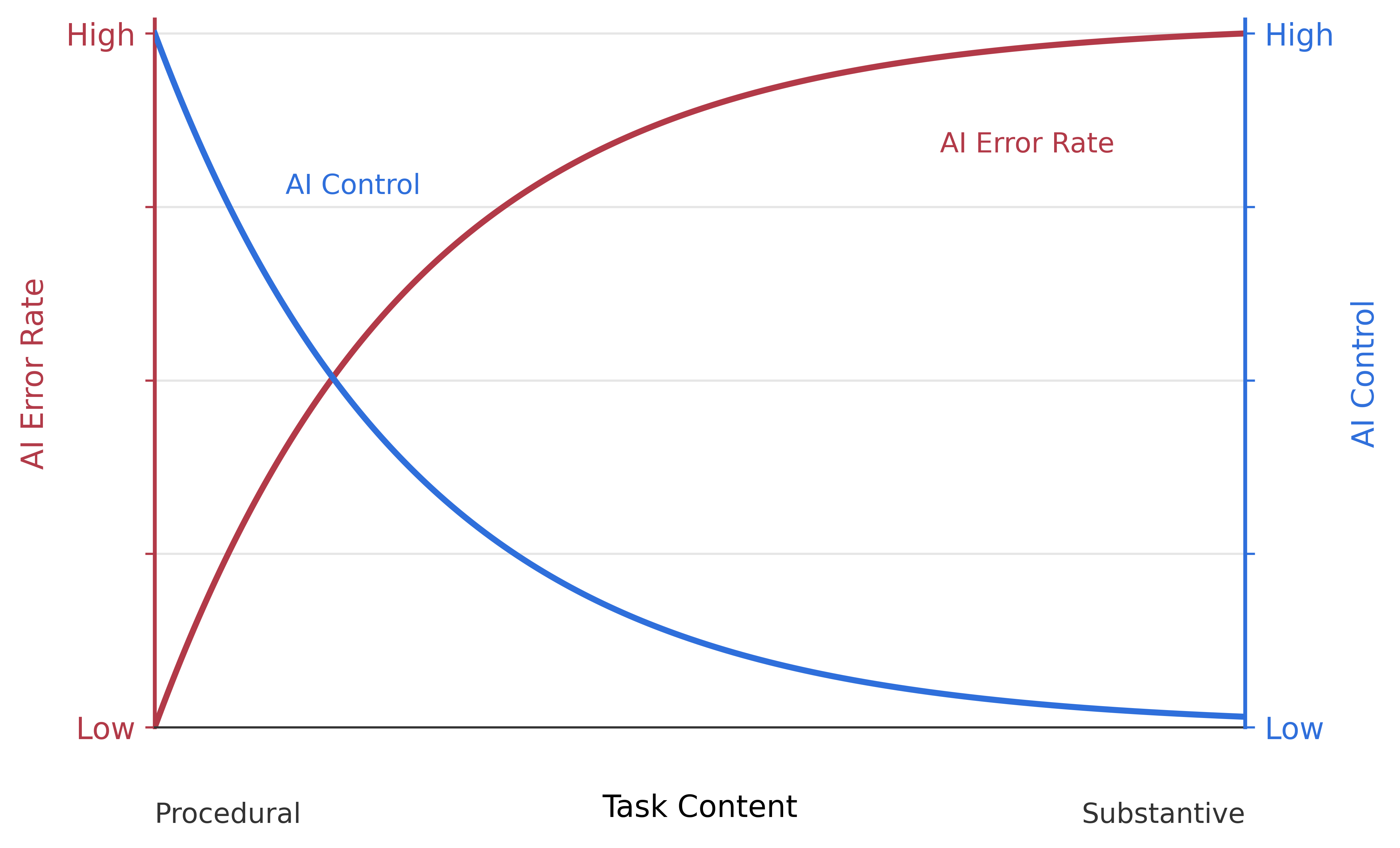
Figure 17.8 sketches the trade-off schematically. As task content moves from procedural to substantive, the AI error rate rises and the share of the work the agent can safely retain falls. The curves are stylized; they capture the qualitative shape of the trade-off rather than calibrating it empirically. The practical implication is the converse of the question above: if the researcher cannot articulate why a task is procedural in their specific case, the task should be treated as substantive and retained.
17.4.2 Radical Transparency: Inputs, Throughputs, Outputs
The second principle holds that the burden of transparency and replication has shifted. Releasing data and code is no longer sufficient. When agents have drafted, decided, or executed parts of the work, a credible replication package must extend three layers further, to the inputs, throughputs, and outputs of the AI-assisted process itself (Spirling 2023; Barrie, Palmer, et al. 2025; American Economic Association 2026; American Political Science Review 2026; Spector-Bagdady 2025). Inputs are the prompts, plans, and context materials given to the agent. Throughputs are the agent’s reasoning trace, intermediate outputs, and sign-off gates. Outputs are the final artifacts tagged with model and version metadata.
Section 17.3.3 described the mechanisms that make this expansion feasible: the project folder treated as a sandbox repository, the asset registry that flags every artifact’s provenance and verification status, the interaction log that records every non-trivial session. The normative claim here is that those mechanisms are not optional good housekeeping. They are the minimum reporting standard for an AI-assisted research process, the precondition for a reader to verify that the locus of control and decision ownership remained with the human researcher (Spector-Bagdady 2025). Implementing them expands the current understanding of a replication package beyond the reproducibility of the quantitative analysis and toward the reproducibility of the research process itself.
The cost of this expansion is real. Authors must log, register, and verify; reviewers must read, cross-check, and judge. The same tools that raise the bar also help meet it. Interaction logs can be maintained in-session rather than reconstructed afterward; asset registries can be updated by the same agents that produce the assets; project-setup skills can scaffold the transparency infrastructure before research begins rather than bolting it on at submission. On the reviewer side, the same logic could apply to standardizing and partially automating the review of AI-assisted submissions, though developing that infrastructure is beyond the scope of this chapter (Munger et al. 2026; Holst et al. 2025).
17.5 Conclusions
This chapter has taken a deliberately workflow-level view of what AI means for social science, and much of my approach can be defended on the ground of accuracy and effectiveness, given current frontier model capabilities. However, in doing so, I have left aside the bigger questions: what becomes of the scientific enterprise when significant portions of its labor can be automated, what is the value of a human researcher when a model can reliably automate much of the research process, and what the academic sector should reward when research output becomes cheaper to produce. These will not be answered in a manual. They will be answered by a messy evolution of disciplinary practice and the many conversations of the future months and years.
But the proposed workflow implies at least partial answers. At the most abstract level, I would argue that the two most fundamental aspects of the scientific enterprise are the direction of research and the error rate of findings. Human control of substantive decisions and radical transparency over the AI-assisted research process are meant to defend these principles.
The transparency principle is the most immediately actionable and possibly controversial recommendation. My stance is that the AI moment calls for an expanded notion of a replication package: not only the data and code that produced a final result, but the inputs, throughputs, and outputs of the AI-assisted process that shaped it (Spirling 2023; Barrie, Palmer, et al. 2025; Spector-Bagdady 2025). What the researcher prompted, which model and version answered, what the agent decided to do, and what the researcher changed afterward all belong in the record (American Economic Association 2026; American Political Science Review 2026; Palmer et al. 2024).
That is a substantial expansion of the reporting burden, both for authors and for reviewers who must engage with it. The consoling point is that the same tools that raise the bar also help meet it. Interaction logs can be maintained in-session rather than reconstructed afterward; asset registries can be updated by the same agents that produce the assets; project-setup skills can scaffold the transparency infrastructure before research begins rather than bolting it on at submission. On the reviewer side, though beyond the scope of this chapter, the same logic could apply to standardizing and automating the systematic review of this process (Munger 2026; Holst et al. 2025).
There are also further risks that remain unaddressed but bear mentioning. The first is to researchers themselves. Agents can do almost every operational task involved in producing a paper, and that possibility threatens a slow erosion of the researcher’s own skills Gerlich (2025). Second, agentic workflows compress research timelines in ways that may undermine the slow, deep thinking social-science training has long relied on, and this paper offers no principled way to calibrate the trade-off between speed and depth (Fan et al. 2025; Prather et al. 2024). Third, uneven adoption is likely to widen productivity gaps between researchers and institutions (Mohammadi et al. 2026; Chugunova et al. 2026), though the relatively low marginal cost of frontier subscriptions offers a partial democratizing countercurrent (Bianchini et al. 2025; Cruces et al. 2026). Finally, environmental externalities, privacy exposures, and the broader societal consequences of automating knowledge work are real and important, though beyond the scope of this paper (Xiao et al. 2025; King and Saade 2026; Carlini et al. 2023).
As a parting thought, what is prescribed here will age – perhaps very quickly. Much of the specific vocabulary, and some of the specific architectural advice, will likely be outdated within six months. The most fundamental meta-skill for researchers in this period is the capacity to keep up with a frontier that moves so quickly. Individual researchers cannot carry that burden alone, and they should not have to. Departments should treat AI-readiness as an institutional responsibility on two fronts: in training, through coursework and apprenticeship that normalize workflows of the kind this paper describes. Similarly, the research community should develop a shared research infrastructure, through shared harnesses, maintained skills libraries, and review routines that make credible reporting feasible at scale.
17.6 Online Appendix
The online appendix collects five complementary artifacts: a startup checklist for researchers opening a first agentic project (Section 17.6.1); a worked example of the prompt-level self-interview on a survey-questionnaire design task (Section 17.6.2); structured descriptions of the three skill protocols that scaffolded this chapter’s production (Section 17.6.3); the schemas and sample entries of the three CSV ledgers that materialize the radical-transparency principle (Section 17.6.4); and an inventory of the full replication package (Section 17.7). The machine-readable sources for the skills and ledgers ship with the replication package.
17.6.1 Startup Checklist
A one-page checklist for researchers already using chat-mode AI who are opening a first agentic project. The five thematic blocks map onto the setup stack of Section 17.3; the closing block runs on the cadence between projects rather than inside any one of them.
Tool
Harness..
Context.
Prompt.
Agent management.
Before the next project.
17.6.2 Self-Interview Worked Example: Survey Questionnaire Design
A concrete illustration of the prompt-level self-interview described in . The task is deliberately domain-standard rather than paper-specific: a survey questionnaire with an embedded information-provision experiment, the kind of instrument a political-behavior or public-opinion researcher builds several times a year. The exchange below is condensed for display; the live session ran longer and included short follow-up clarifications on most items.
The researcher opens a fresh agent instance and starts with a minimal framing prompt rather than a full specification. The point is to make the agent interview her, not to produce a plan she has already written:
The eight questions below are the ones the agent asked, in order. Each corresponds to a decision that is load-bearing for the instrument’s validity and that the researcher’s domain knowledge strictly dominates a model default on.
- Population, sampling frame, and mode. Who exactly are the respondents — a specific professional society’s member list, a commercial panel, departmental contacts? What is the mode (web, phone, in-person) and what is the field period? members of three professional associations; web-only via Qualtrics; two-week field period opening on a Monday.
- Constructs and measurement. Which dimensions of “adoption” are in scope — behavioral frequency, tool familiarity, attitudes, perceived norms? For each, do you want an existing validated scale where one exists or discipline-specific new items? behavioral (past-30-day use by research task), attitudes (approval and concern), perceived norms; published scales for attitudes, new items for behavior because existing instruments don’t map to research tasks.
- Experimental design. What are the arms of the embedded experiment, what is the randomization unit, and which outcomes go pre- versus post-treatment? Do you want blocking on any pre-treatment covariates? two arms (short factual statement on AI capability levels vs. control); unit is the respondent; demographics and prior use pre-treatment, attitudes and policy items post-treatment; block on discipline.
- Length budget and priority order. What’s the target median completion time, and which blocks would you cut first if we go over budget? 12 minutes median; priority order behavioral block, experiment, attitudes, norms, demographics; drop norms first.
- Sensitive or politically loaded items. Any items sensitive enough to warrant explicit non-response options, branching, or reverse-coded balance? Any items you want order-randomized to mitigate priming? randomize order within the attitudes block; offer “prefer not to answer” on institutional-affiliation items; no reverse coding needed on already-balanced validated scales.
- Data-quality safeguards. Which quality checks — attention checks, instructional manipulation checks, speeding and straight-lining flags, bot screens — should be built in, and where should they sit? one attention check mid-survey; one IMC after the experiment; speeding flag at one-third of median; reCAPTCHA at entry; no straight-lining flag — no grid items long enough to warrant it.
- Pre-registration and codebook. Are we pre-registering the instrument and the experiment’s hypotheses? Should the deliverable include a codebook with stable item IDs so analysis code can reference them? yes, pre-register on OSF before fielding; codebook with stable item IDs, one row per item, variable labels ready to reuse in Stata.
- Output formats and sign-off gates. What should the final artifact be — a Qualtrics QSF, a plain-text item bank for import, a LaTeX appendix version for the pre-registration, or all three? Who signs off before fielding, and how many pilot waves? QSF, LaTeX for the pre-registration, and a CSV codebook; two pilot waves (N=10 cognitive, N=50 quantitative), each with explicit sign-off before the next.
The eight questions moved the prompt from “design a survey on AI adoption” to a plan that specifies population and mode; which constructs use validated scales versus new items; the experimental arms, randomization unit, and pre/post covariate placement; length budget and priority ordering for cuts; sensitivity handling and order randomization; data-quality checks and their placement; pre-registration commitment and codebook schema; and deliverable formats with two-stage pilot sign-off. Each of these is a decision the researcher would otherwise have delegated implicitly — and, in most cases, one the model would have defaulted on silently rather than asked about.
The questions are not a generic survey-methods checklist. They were selected under two filters. : getting the answer wrong changes the validity of the instrument, not merely its polish. : the researcher’s answer strictly dominates a model default. Items the agent can reasonably default on — wording of validated scale items, response-option phrasing for standard demographics, ordering of attention-check wording — are deliberately absent. A self-interview that hits the load-bearing, domain-dominant decisions is short (five to eight questions is typical) and produces a prompt plan dense enough that the subsequent drafting session is mostly execution. The alternative, a long initial prompt written without the interview, tends to over-specify the easy decisions and under-specify the hard ones.
17.6.3 Skill Protocols
The replication package ships three Markdown skills that this chapter’s production exercised end to end: project-setup.md, skill-writing.md, and lit-review-protocol.md. Each is an interview-driven playbook rather than a prose essay. An agent reads the skill on invocation, walks the researcher through its phase-ordered interviews, and commits artifacts only after explicit sign-off. The three compose: project-setup scaffolds the folder the others write into; skill-writing produced the lit-review-protocol (and itself); and lit-review-protocol runs as a subagent inside skill-writing whenever a new skill needs external grounding.
17.6.3.1 project-setup.md — scaffold a transparent project folder
Invoked at project inception. The skill asks for the project title, type (empirical research, position paper, literature review, data exploration, or methodological), and any project-specific rules, then (i)~creates the directory layout of Figure~\(\ref{fig:project-setup}\), pruning branches that do not apply; (ii)~generates a filled-in README.md carrying the nine universal rules of engagement listed below; (iii)~translates the researcher’s outline into a checkable implementation-roadmap.md; and (iv)~initializes the two transparency ledgers asset-registry.csv and interaction-log.csv, whose schemas are given in . Together, these artifacts are the operational expression of the radical-transparency principle: every asset in the project has a row and every non-trivial session has a row, and both are created at inception rather than reconstructed at submission.
- Researcher retains control. No substantive decision (design, interpretation, final phrasing, model or method choice) is made by an agent without explicit user sign-off.
- One instance, one task. Start each non-trivial task in a fresh agent instance with a focused plan. Do not accumulate unrelated threads in a single context.
- Read-only source material. Never modify files in
inputs/} (empirical projects) orbackground/} source material. Derived artifacts go elsewhere. - Register every new asset (draft, figure, table, script, dataset, note, reference) in
asset-registry.csv} with a creator flag (human} /agent} /mixed}) and verification status (not-verified} /partially-verified} / `human-verified}). - Log every non-trivial session in `interaction-log.csv} with date, input and output summaries, model metadata, and assets affected.
- Archive, don’t delete. Move obsolete files to the nearest `archive/} subfolder rather than removing them.
- Consult `implementation-roadmap.md} before starting work and update it as steps complete.
- Skill orchestration. For any complex task, first check the skill library. If no skill fits, ask the user whether to create one before improvising.
- Validation by default. Prefer deterministic validation checks (tests, reproducibility runs, cross-source comparisons) over agent self-assessment.
17.6.3.2 skill-writing.md — write a new skill
Invoked when a recurring task keeps being re-specified, an existing skill has aged, or a team wants to institutionalize a shared practice. The protocol runs six phases: (0)~identify the need and write a scope statement; (1)~gather artifacts from the researcher’s own prior work and dispatch a subagent to extract recurring moves, recurring decisions, and implicit rules; (2)~gather external sources, calling the lit-review protocol as a subagent when outside grounding is load-bearing; (3)~polish-the-skill interview, surfacing preferences, anti-patterns, and review cadence that the artifacts did not settle; (4)~draft the skill following a standard skeleton (triggers, artifacts, universal rules, phases, handoffs, failure modes, worked example); and (5)~test on one real task and revise. The central anti-pattern the skill warns against — and the one most often surfaced on first invocation — is the training-memory skill: a skill that reads as a textbook summary of the genre rather than as this researcher’s practice, and that is the default output whenever the artifact-mining and self-interview phases are skipped.
17.6.3.3 lit-review-protocol.md — structured agent-assisted literature review
Invoked when a paper needs a new literature review, an existing review needs expansion, or raw deep-research output needs to be normalized and filed. Four active phases plus a maintenance phase: (1)~scope the strands — turn the paper’s outline into a named list of strands with rationale, target sections, anchor sources, and qualitative constraints, approved before any search runs; (2)~draft prompts — one per strand, built by merging a permanent agent-facing template with a per-strand context block (research questions, anchors, scope overrides, exclusions); (3)~ingest — validate BibTeX, resolve every DOI, dedupe against existing references.bib, append verified entries, and open a row in classification.csv tagged partially-verified until the researcher reads; (4)~classify and map — every source gets strand, sections, evidence\_type, reliability, and read\_status, and sources slated for citation get a per-source Markdown note. Phase~5 maintains the review continuously as drafting surfaces new sources. Two hard rules together implement radical transparency on the literature side: never invent a DOI or venue, and never promote a source to human-verified until the researcher has read it.
17.6.4 Ledger Schemas and Sample Entries
The three CSV ledgers that materialize the radical-transparency principle all ship with the replication package. This section reports their schemas (columns, admissible values, short gloss) and a handful of sample rows drawn directly from the files that produced this chapter. Long free-text fields are abridged for display.
17.6.4.1 asset-registry.csv
asset-registry.csv.
| Column | Values | Gloss |
|---|---|---|
asset_path |
free text | Relative path from project root. |
asset_type |
draft \| figure \| table \| script \| dataset \| note \| reference \| other |
|
creator |
human \| agent \| mixed |
Provenance flag. |
model_metadata |
free text | Model ID + harness, e.g., claude-opus-4-7 / claude-code. Blank if human. |
created |
YYYY-MM-DD | |
last_modified |
YYYY-MM-DD | |
verification |
not-verified \| partially-verified \| human-verified |
|
notes |
free text | Purpose, known issues, review status. |
asset-registry.csv of this chapter’s project folder. The asset_type, model_metadata, created, and last_modified columns are omitted for space.
asset_path |
creator |
verification |
notes (abridged) |
|---|---|---|---|
background/concepts/outline.txt |
human |
human-verified |
Source-of-truth outline. |
tables/table1-vocabulary.tex |
agent |
not-verified |
Table 1 v2; ten rows in two blocks. |
appendix/skill-writing.md |
mixed |
partially-verified |
Full six-phase skill; expanded by agent from an 18-line human brainstorm. |
background/literature/references.bib |
mixed |
partially-verified |
Seeded with four anchor entries; Zotero import target. |
ai-agent-draft.tex |
agent |
not-verified |
Snapshot of first full-paper drafting pass, preserved for diffing. |
17.6.5 interaction-log.csv
interaction-log.csv.
| Column | Values | Gloss |
|---|---|---|
date |
YYYY-MM-DD | |
session_id |
short identifier | e.g., 2026-04-21-a. |
harness |
claude-code \| chatgpt \| codex \| antigravity \| other |
|
model |
model ID | e.g., claude-opus-4-7. |
researcher_input_summary |
1–2 sentences | |
agent_output_summary |
1–2 sentences | |
assets_affected |
comma-separated paths | Should match entries in asset-registry.csv. |
notes |
free text |
interaction-log.csv of this chapter’s project folder. The date, harness, assets_affected, and notes columns are omitted for space; input and output summaries are further abridged.
session |
model |
researcher_input (abridged) |
agent_output (abridged) |
|---|---|---|---|
2026-04-21-d |
claude-opus-4-7 | Finalize the Phase-1 strand list: accept the five landscape strands plus transparency, control, cognitive effects, and ethics; split AI-methods into two strands; merge the trust-related strands. | Rewrote lit-review-strategy.md with the approved eight-strand list; reorganized lit-review-prompts.md; reclassified four anchor sources in classification.csv. |
2026-04-21-h |
claude-opus-4-7 | Enrich the commented outline, draft the chapter section by section, author the four figures and Table 1. | Wrote the full v1 of the chapter: abstract, sections 1–4, appendix stub; authored four TikZ figures inline; copied main.tex to the project root as ai-agent-draft.tex. |
17.6.6 classification.csv
classification.csv.
| Column | Values | Gloss |
|---|---|---|
citekey |
free text | Matches references.bib. |
strand |
comma-separated strand IDs | From lit-review-strategy.md. |
reliability |
high \| medium \| low |
Flagged by the search agent per the prompt template. |
sections |
comma-separated | Outline section numbers, e.g., 1.1,3.1. |
evidence_type |
empirical \| conceptual \| methodological \| normative \| review |
|
read_status |
unread \| skimmed \| read |
|
verification |
not-verified \| partially-verified \| human-verified |
|
note_file |
path | Per-source Markdown note, if one exists. |
notes |
free text | One-line hook. |
classification.csv of this chapter’s project folder, showing the four anchor sources seeded at project inception. All four currently sit at partially-verified; the Stage 6 review pass promotes cited sources to human-verified. Strand IDs refer to the eight-strand scheme in lit-review-strategy.md.
citekey |
strand |
reliability |
sections |
evidence_type |
read_status |
|---|---|---|---|---|---|
gordon2025datanomad |
A2 | high | 3.3, 4.2 | methodological | skimmed |
hai2026index |
L1, A2, B2 | high | 1.1, 3.1, 4.1, 4.2 | empirical | skimmed |
pepinsky2026agentic |
A1, A3 | low | 1.1, 3.5, 4.1 | normative | read |
spirling2023nature |
A2 | high | 3.1, 4.2 | normative | skimmed |
17.7 Replication Package
The full replication package is the project folder that produced this chapter. It ships as a Dropbox mirror at AI in Social Science Research/ and is available from the author on request. Beyond the three skills described in and the ledgers catalogued in , the package contains:
README.mdandimplementation-roadmap.md— the filled-in rules of engagement and the living to-do list agents consulted throughout the project.asset-registry.csv— one row per artifact (draft, figure, table, script, note, reference), with creator flag (human/agent/mixed), model metadata for agent and mixed artifacts, and verification status. Every asset referenced by the final chapter is traceable here.interaction-log.csv— one row per non-trivial AI-assisted session from project inception through submission, with date, harness, model, input and output summaries, and assets affected. The log is the reconstructible record a reviewer needs to audit the AI’s role.background/literature/— the materialized output of the lit-review protocol:references.bib,classification.csv, per-strand prompts and raw outputs underai-inputs/, researcher-sourced material underhuman-inputs/, and per-source notes at<citekey>.md.background/concepts/andbackground/feedback/— concept notes and colleague, advisor, and reviewer feedback carried across sessions.drafts/— includingai-agent-draft.tex, an early agent-produced draft of this chapter, preserved alongside the final version so a reader can diff the two.figures/,tables/,scripts/— sources and derived artifacts for every figure and table the chapter prints.appendix/— the three skills above in Markdown plus the startup checklist, preserved in machine-readable form so a future researcher can drop them into their own skill library.
A reader who treats this chapter as a methodological reference can inspect the project folder itself as a worked example of the practices advocated: the same folder layout, the same asset registry, the same interaction log, scaled to a published paper rather than a toy.
In practice, most chat interfaces now include agentic capabilities through a virtual sandbox, though usually neither persistent nor user-accessible↩︎
These harnesses differ substantially in design, capability, and pricing, and most are proprietary. A feature-by-feature comparison is beyond the scope of this chapter.↩︎
In the online supplementary material, I provide two versions of this skill, one for new projects and one for projects already underway↩︎