16 Quantifying Culture from Embeddings to Generation
Laura K. Nelson
Sociology, University of British Columbia
laura.k.nelson@ubc.ca
Tom Einhorn
Sociology, University of British Columbia
Abstract
Measuring culture has long been a core sociological pursuit. The emergence of word embeddings in the 2010s offered a new approach to quantify culture by representing systems of meaning as mathematical relationships among concepts, allowing scholars to compare how these systems of meaning vary across social groups, historical periods, and community contexts. Recent advances in artificial intelligence have complicated the promise of embedding methods. Transformer-based language models incorporate vastly larger contexts and represent meaning dynamically, bringing computational models potentially closer to the scale and contextuality of human language use. Yet these advances have come at a cost. Contemporary foundation models aggregate information across languages, communities, and historical periods, producing representations that are increasingly detached from identifiable social standpoints. This creates a paradox for quantitative cultural research: models now track cultural information across much larger contexts than any human could, yet they are less clearly tied to the situated perspectives through which culture is experienced and learned by humans. This chapter traces the trajectory from static embeddings to contemporary large language models and examines the implications of this shift for the formal modeling of culture. We review how static embeddings were used to measure cultural associations and we consider emerging evidence that large generative models struggle to reproduce the diversity and variance observed in human populations. We then examine two provisional solutions: steering methods that attempt to recover latent perspectives from within large models, and historically or socially bounded models designed to preserve identifiable cultural standpoints. We conclude that the central challenge facing computational cultural sociology is determining whether perspective can be meaningfully modeled within increasingly powerful language models.
AI usage statement: ChatGPT and Lumo were used sparingly for feedback on clarity and flow of some paragraphs and sentences. The authors undertook all substantive conceptual development and made all argumentative and interpretive decisions. The authors take full responsibility for the content of this publication, including its claims, citations, and conclusions.
16.1 Introduction
Culture is among the most central yet elusive concepts in sociology. Sociologists argue that culture shapes how people understand the world, how they classify objects and people, draw boundaries, develop identities, and coordinate action (Beaman 2015; DiMaggio 1987, 1997; Lamont and Molnár 2002; Swidler 1986). Yet culture is difficult to cleanly operationalize and measure. Sociologists have developed a wide range of strategies for measuring culture, from surveys of beliefs and values to analyses of classifications, narratives, texts, images, and symbolic boundaries (Alexander 2015; Jepperson and Swidler 1994; Marsden and Swingle 1994; Mohr 1998; Mohr and Duquenne 1997). But the slipperiness of culture, including how to even define the term (is it just the water we all swim in? e.g., Sewell (1999); Wallace (2009); Williams (1976)), has meant persistent discussions and debates over how to measure culture. Some of the history of the sociology of culture can be read as an effort to develop better ways of observing and measuring these systems of meaning (Alexander 2015; Mohr 1998).
The emergence of computational methods offered a new avenue to address this question (Bail 2014; Carley 1994; DiMaggio et al. 2013). Beginning in the mid-2010s, word embeddings moved to the center of the debate around how to best represent cultural meanings mathematically (Boutyline et al. 2023; Boutyline and Arseniev-Koehler 2025; Stoltz and Taylor 2021; Voyer et al. 2022). Static word embeddings transform words and concepts into vectors whose positions may reflect their relationships to one another in a semantic space. Empirically, researchers used these methods to, for example, measure stereotypes (Boutyline et al. 2023), symbolic boundaries (Voyer et al. 2022, 2022), and moral classifications (Arseniev-Koehler and Foster 2022) directly from text. More theoretically, embeddings provided a new measurement tool to formally model culture in language, allowing systems of meaning to be measured and compared across groups and historical periods (Boutyline et al. 2023; Stoltz and Taylor 2021). Researchers could also examine how different social positions produced different systems of association and how those associations reflected broader structures of power and inequality (Nelson 2021), operationalizing the concepts of situated knowledges and lived experiences (Nelson 2022).
More ambitiously, embeddings offered a plausible computational model of how culture itself emerges or is learned (Arseniev-Koehler and Foster 2022; Foster 2018). The distributional hypothesis—that words acquire meaning from the contexts in which they appear—echoed longstanding sociological and philosophical theories arguing that meaning emerges through social use and practice (Bourdieu 1984; Strauss and Quinn 1998; Swidler 1986). In different ways, Wittgenstein’s account of language games, Mead’s theory of the social self, Saussure’s meaning as position within relational systems, and more recent computational theories of culture (Boutyline and Arseniev-Koehler 2025; Foster 2018; Kozlowski 2026) each, in different ways, anticipate that culture either emerges through, or, more strongly, that people learn culture by, encountering patterns of association embedded in their experiences and interactions with the world, and then generalizing out from those patterns. This convergence between social(linguistic) theory and computation made embeddings attractive to sociologists of culture.
Recent developments in artificial intelligence have complicated this picture. Transformer architectures and the resulting language models have dramatically expanded the scale and capabilities of computational representations (Davidson 2024; Jensen et al. 2022). They incorporate larger contexts, richer semantic information, and far more textual material than earlier embedding models. At the same time, they have moved further away from one of the properties that made embeddings so useful for cultural analysis: their ability to represent socially identifiable perspectives. Previously, word embeddings models were often trained on specific and known textual corpora. The corpus was the perspective (Pardo-Guerra and Pahwa 2022). Train a model on text from a specific era, community, or geographic location, and the resulting embedding space could be read as representing the semantic geometry that emerges from that context (Kozlowski et al. 2019). Contemporary foundation models aggregate information across languages, communities, genres, historical periods, and more. They encode immense amounts of information, yet they do so without corresponding to any obvious social location. In that sense, they are at once more and less than human. Their scope exceeds anything a single person could occupy, yet they are situated nowhere in particular, occupying no recognizable cultural standpoint. The result is a paradox at the center of contemporary computational social science. Models have become increasingly capable of representing something like humans and the social world, even if uncannily so, yet it is no longer clear whether models can formally represent society or culture in the way that earlier computational theories envisioned (see, e.g., Arseniev-Koehler and Foster (2022) for an articulation of this promise).
This chapter examines this tension. We argue that the trajectory from static embeddings to contemporary large language models has produced a shift in what computational methods represent. Earlier embedding models provided tools for measuring systems of meaning and disentangling perspectives. Contemporary foundation models, alternatively, increasingly represent amalgams of perspectives rather than perspectives themselves. As we describe below, this shift helps explain why concerns about bias that dominated earlier work are increasingly accompanied by concerns about variance and homogeneity in contemporary work. More broadly, this chapter raises a fundamental question for the future of quantitative cultural analysis: can computational models continue to serve as formal models of culture if they no longer correspond to the situated perspectives through which culture is ostensibly experienced and learned? In other words, can a model that has encoded everyone’s culture still represent anyone’s?
16.2 Algorithmic Bias as a Sociological Resource
Debates about what culture is and how it can be measured aside, virtually all sociologists understand that social and cultural associations are embedded in the structure of the language we use. This fact is part of what makes culture so pervasive, and culture so difficult to disrupt. Indeed, culture is defined (by most) as the shared meanings, classifications, assumptions, and interpretive frameworks through which people understand the world and coordinate social action (Alexander 2003; Geertz 2009; Swidler 2005), and word and concept associations embedded in language constitute one part of that culture. As such, sociologists have long sought to map these systems of meaning in language (following scholars such as Wittgenstein and Mead, language includes words, text, images, and gestures). Sociologists ask questions such as what associations in language connect social categories, identities, institutions, and practices (Mohr 1998; Mohr and Duquenne 1997)? When do these associations emerge, and how do they change over time (DiMaggio 1987)? And how do they vary across groups, organizations, places, and historical periods (DiMaggio 1987; Griswold 1987; Lamont and Molnár 2002)? These cultural associations are core to the social world, as they shape perception, evaluation, and action, and in doing so, they may also contribute to sustained patterns of social inequality (Bourdieu 1984; Lareau 2015; Rivera 2012). Sociologists of culture also go beyond measuring culture, seeking to explain how culture is learned and reproduced. How do shared meanings become taken for granted? How do they become embedded in cognition? And how do systems of meaning come to shape the way individuals understand and navigate the social world?
Computational methods, particularly embeddings, have provided new ways of studying culture quantitatively, at least as it presents via language. Embeddings have expanded both what aspects of culture we are able to measure and what kinds of data we are able to use to measure them. They have made it possible to formally model culture as a system of symbolic associations, allowing researchers to quantify how concepts, identities, institutions, and social categories relate to one another within a shared meaning space (Arseniev-Koehler and Foster 2022; Kozlowski et al. 2019; Stoltz and Taylor 2021). And, as stated above, for some, embeddings have simultaneously provided a computational analogue for how cultural meanings are learned through exposure to language (Arseniev-Koehler and Foster 2022; Foster 2018).
The use of embeddings to study culture assumes that embeddings accurately capture the social and cultural associations sociologists theorize are conveyed, in part, through language. One of the pivotal moments revealing this potential use of embeddings came in 2014 with the release of Google’s word2vec model, trained on Google Books and Google News. At the time, it was the largest and most influential word embedding model available. Researchers immediately discovered that the model encoded a wide range of social associations, particularly around gender (Bolukbasi et al. 2016). Words closest to “she” included terms such as “homemaker,” “nurse,” “receptionist,” and “librarian,” while words closest to “he” included “maestro,” “skipper,” “protégé,” and “philosopher.” The model also reproduced stereotypical gendered analogies, such as woman is to sewing as man is to carpentry and woman is to nurse as man is to surgeon, alongside more straightforward gender relations such as woman is to queen as man is to king. For computer scientists, these patterns were evidence that (undesirable) social biases had become embedded in their model and they subsequently approached this as a debiasing problem (Bolukbasi et al. 2016). They attempted to subtract “problematic” gender associations (woman is to nurse as man is to surgeon) while preserving semantically productive analogies (woman is to queen as man is to king). If these systems are used in the world, to, for example, create an algorithm to sort job applications, this type of gender bias can, of course, be dangerously harmful.
For sociologists and other scholars interested in culture, however, these associations suggested that embeddings were recovering meaningful features of the social world encoded in language. This gave rise to a large research agenda. Scholars used static embeddings to measure changing gender stereotypes over time (Boutyline et al. 2023), moral associations around body size and health embedded in language (Arseniev-Koehler and Foster 2022), changing associations between class (Voyer et al. 2022) and immigration (Voyer et al. 2022) and etiquette, and semantic change in political concepts over time (Rodman 2020). When word embeddings exhibit what some scholars call algorithmic fidelity (Argyle et al. 2023), that is, when the relationships captured by the model corresponded to meaningful relationships in the social world, they became a powerful tool for measuring culture quantitatively.
This research agenda expanded to cultural learning, offering a potential plausible model of how cultural meanings are learned. If, as posited by the distributional hypothesis, words derive their meanings from the contexts in which they appear, embedding models operationalize this idea by learning representations of words from patterns of co-occurrence across large corpora of text. This matches some social theories of language (Wittgenstein 1953), which posit that meanings of words are learned via practice, not through formal definitions or their correspondence with things in the world (i.e., the Aristotelian theory). In other words, individuals learn cultural and linguistic meanings by observing patterns in their environments and through their experiences and generalizing from those (limited) observations (Foster 2018). Individuals come to understand, for example, what occupations are associated with men or women, what behaviors are respectable or deviant, and what identities are linked to authority or marginalization through repeated encounters with these associations in everyday life.
Whether or not embeddings accurately reproduce the full complexity of human cultural or linguistic learning, or mimic human learning at all, they offered sociologists of culture a tractable representation of a core sociological and linguistic insight: that meaning might arise relationally, through patterns of association, rather than existing as an intrinsic or rule-based property of words/symbols/gestures.
16.3 Language, Meaning, and Situated Perspective
If sociologists understand that meaning arises relationally, they also understand that control over meaning is not distributed evenly across a population (see, e.g., the concept of symbolic capital via Bourdieu (1984), Bourdieu (1986), Bourdieu (2008)). Theorists have argued that people occupy different positions within systems of meaning, experiencing the world through different social locations, granting symbols and meaning different relationships to power across communities (Collins 2000; Fanon 2008; Haraway 1988; Moraga and Anzaldua 1984). Du Bois’s concept of double consciousness illustrates this point. Black Americans, Du Bois argued in the early 20th century, were compelled to understand themselves not only through their own experiences, but also through a White gaze structured primarily by “contempt and pity” (Du Bois [1903] 1994). Cultural meanings are thus refracted through unequal social positions, producing distinct embodied perspectives on the same social world. Perspectives which are subject to this symbolic subjugation create psychic burdens on communities without cultural power, such as, historically, Black Americans or colonized people (Fanon 2008). Meaning as such may be socially produced, but access to meaning, authority over meaning, and experiences of meaning are distributed unequally.
Fortuitously, embeddings also provided a way to measure these perspectival differences computationally, offering a way to operationalize the idea that social actors in the same institutional space still inhabit different cultural worlds. Researchers could, for example, train models on specific corpora, isolate demographic vectors, and then analyze how associations between word vectors differed from the “vantage” of social positions, approximating how different groups experience the world and thus how these groups might create different generalized cultural understandings (e.g. the concept of the generalized other via Mead (1997)). Consider the case of Black and White women in the nineteenth-century U.S. South. These groups occupied dramatically different social worlds, despite living within the same geographic region and institutional order. Nelson (2021) used word embeddings trained on nineteenth-century southern narratives to demonstrate the potential of embeddings to measure different perspectives. By using vector addition and subtraction to isolate intersecting social positions, such as Black women and White women, it became possible to examine how these groups were situated within broader systems of meaning. In this corpus, both Black women and White women were more closely associated with the domestic sphere than men. At the same time, Black women were more strongly associated with the economic sphere, while White women were more strongly associated with the cultural sphere. These patterns reflected the intersecting and diverging social worlds occupied by Black and White women in the nineteenth-century South; worlds structured by gender, slavery, racial domination, unequal labor relations, and sharply divergent access to social and cultural institutions. Importantly, they demonstrated that we can plausibly measure what it means that groups occupy different symbolic positions within the same society through measuring different structures of association embedded in language. The meaning and vantage point of vectors representing the economy, the domestic, high culture, etc., shifted in relation to different intersecting identity vectors. If we believe Foster (2018), that culture is learned by generalizing from limited experiences, and those experiences across social groups are dramatically different (as is the case in the nineteenth-century US South), then the same vector will “look” different across social groups. High-dimensional word embeddings, in other words, offered a quantitative approach to studying Haraway (1988)’s situated knowledges or Beauvoir ([1949] 2011)’s lived experience: culture as multiple partial perspectives shaped by unequal positions within a social structure.
This illustrates the broader contribution of embeddings to the sociology of culture: embeddings allowed researchers to measure how systems of meaning were constructed, and how they varied across social perspectives. These early studies relied primarily on static embeddings and relatively simple vector operations (for a critique, see Loon et al. (2022)). Researchers isolated perspectives through carefully constructed corpora and examined differences through vector addition, subtraction, and similarity measures. While powerful, these approaches treated perspectives as fixed positions within a stable semantic space. The next generation of embedding models introduced more sophisticated ways of representing context and perspective.
16.4 Large Language Models and the Collapse of Perspective
The transformer revolution, inaugurated by the publication of “Attention Is All You Need” in 2017 (Vaswani et al. 2017), provided a new way of representing these contextual differences. Rather than assigning a single vector to each word, transformer models generate representations dynamically based on the surrounding text. A word appearing in one sentence is represented differently than the same word appearing in another. Meaning becomes conditional on context rather than fixed across an entire corpus. For the sociology of culture, this was a significant advance. Static embeddings were effective at measuring stable systems of association, but dynamic embeddings allow vectors to shift across social and linguistic contexts, providing new tools for modeling culture as a system that is properly contextualized. In principle, this could bring computational models closer to sociological theories that view meaning as both contextual and perspectival.
The major families of encoder-only transformer models, such as BERT, were among the first widely-used models to represent meaning dynamically (Devlin et al. 2019). But these models remain constrained by relatively short context windows. People do not learn word meanings or cultural associations from a few surrounding words or sentences alone. We are bound by constrained memory, but not context windows. People accumulate cultural knowledge across years of experience, drawing connections across experiences and lifetimes. Consider the case of a novel. When we read a novel we can carry themes, characters, and symbols from the beginning of a novel to its conclusion, even if the novel is hundreds of pages long. Encoder-only models like BERT captured local context far more effectively than static embeddings, but they still operate over context windows that are much smaller than the experiential contexts through which humans acquire and deploy cultural knowledge. Generative, or decoder-only, models extended language model capabilities even further, and specifically, to incorporate more context into their embedding representations. Because decoder-only models skip the computationally expensive encoding step, they can incorporate much larger context windows, drawing on thousands or even millions of tokens when generating a response to a prompt. This development is potentially significant for the study of culture because, as cultural meanings are rarely learned or gain meaning from isolated utterances, generative models could, in theory, move us closer to a formal, computational representation of cultural meaning. These models can, for example, integrate information across much larger bodies of text than earlier embedding models, capturing associations that emerge only at broader scales that go beyond encoder-only models yet at scales that people can still hold in their heads.
Yet this development has created a paradox for the sociology of culture, one that currently limits our ability to use these models to formally study culture. On the one hand, generative large language models can incorporate vastly more context than earlier embedding models and can draw connections across enormous bodies of text. In this respect, they potentially more closely model human cultural learning than static embeddings and encoder-only contextualized embeddings. On the other hand, these models contain far more information than any individual person could ever acquire. An individual has a lifetime of experience that shapes their cultural understandings, yet, even for those who read widely, no human being can read and recall the multilingual corpus, historical archives, websites, books, news articles, and conversations that constitute the training data of a contemporary foundation model. In other words, humans experience the world from particular social positions, inhabiting a specific, limited set of experiences and exposure to knowledge from which we generalize. Foundation models, in all of their breadth, are untethered from these situated perspectives. Earlier embedding approaches allowed researchers to model such perspectives directly by training on specific corpora and carefully parsing the resulting semantic spaces. A model trained on nineteenth-century southern narratives captures a different structure of associations than a model trained on contemporary newspapers because these models are created using a bounded collection of texts. Large language models, by contrast, aggregate an enormous number of perspectives, historical and contemporary and across the globe, into a single representational system. They do not correspond to any particular community or historical moment, and at least at the time of writing this chapter, researchers can not easily isolate the perspectives that have been combined within them.
Herein is the fundamental paradox for the current moment in quantitative and formal modeling of culture using embedding models. Embedding models have become more capable and often more accurate across a variety of tasks (for just one example, see Bonikowski et al. (2022)). At the same time, they have moved further away from the original promise that made embeddings so attractive to sociologists of culture: the ability to formally model situated systems of meaning. The challenge for the near future is therefore to assess whether sociologists of culture can indeed use these new models to measure cultural systems in the ways we have previously developed with static embeddings, and that we were just starting to explore with (encoder-only) contextualized embeddings.
16.5 Challenge #1: Homogeneity and a Lack of Variance
The rapidly growing literature on generative AI simulations illustrates the above paradox. Researchers are exploring whether large language models can be used to simulate individuals, organizations, communities, or entire populations. Such simulations could make it possible to study questions that are difficult or impossible to investigate through conventional methods alone, because of cost or ethical constraints (Park et al. 2024), or the simple fact that the population of interest no longer exists (Varnum et al. 2024). Historical populations are a particularly compelling example. If models could accurately reproduce the perspectives of people in the past, they could provide new ways of investigating historical change and cultural diffusion, among other topics (Skarpelis 2026; Varnum et al. 2024). Yet evaluations of these simulations have produced a consistent finding: current large language models do not accurately reproduce the distributions of opinions, beliefs, or behaviors observed in known human populations. When prompted to answer survey questions (Argyle et al. 2023; Boelaert et al. 2025; Kozlowski and Evans 2025), participate in experiments (Park et al. 2024), or generate open-ended responses (Zhang et al. 2025), their outputs tend to cluster around a relatively narrow range of positions. This is true even when researchers attempt to simulate specific demographic groups or individual personas (Barrie and Cerina 2026). The central challenge is the homogeneity, or the lack of variance, in large language models. While contemporary foundation models are remarkably knowledgeable along some axes, these enormous, high-dimensional models compress information into a narrow representational space that makes it currently difficult to justify their use to simulate humans in a way that would be useful for social science.
One possible explanation for this narrow range of representations comes from the Platonic Representation Hypothesis (Huh et al. 2024). The authors’ argument is that sufficiently capable models trained on sufficiently broad tasks may converge toward similar internal representations of the world, even when different training data and architectures are used. The authors propose three possible mechanisms for this convergence. First, as training data and tasks become more general, models face an increasing number of constraints. Every additional document, language, or task narrows the range of representations that can successfully fit the data. Over time, the set of viable representations shrinks, pushing models toward similar solutions. Second, larger models may be better able to discover these narrow but generalizable solutions. As model capacity increases and optimization improves, models trained on similar objectives increasingly converge toward the same representational optimum, even when they differ in architecture or training details. Third, neural networks exhibit a simplicity bias. Among the many possible representations that could fit the data equally well, learning dynamics tend to favor simpler and more compressed representations. As models scale, they may therefore converge both on similar outputs and on increasingly similar internal organizations of information.
For the sociology of culture, the platonic representation hypothesis is troubling. If increasingly capable models converge toward a common representation of the world, then homogenization may not be a temporary limitation of current systems but an expected consequence of scale. Larger (and often more capable) models would become increasingly effective at representing aggregate human experience as a simulacrum while simultaneously becoming less representative of any particular social position. The very forces that improve model performance may also move models further away from the situated and perspectival understandings of culture that sociologists seek to understand.
16.6 Potential Solution #1: Steering Large Language Models
What is a quantitative sociologist of culture to do? One possible response to this reality comes from the growing literature on mechanistic interpretability and steering. The central premise is that large language models may contain far more variation than is visible in their default outputs. Rather than treating a model as a black box or a next token predictor, researchers attempt to identify internal features associated with particular concepts or modes of reasoning and then manipulate those features directly to intentionally steer output. The hope is that the perspectival associations sociologists claim are in language have not disappeared entirely in large language models. Instead, they may be latent within the model and recoverable through intervention.
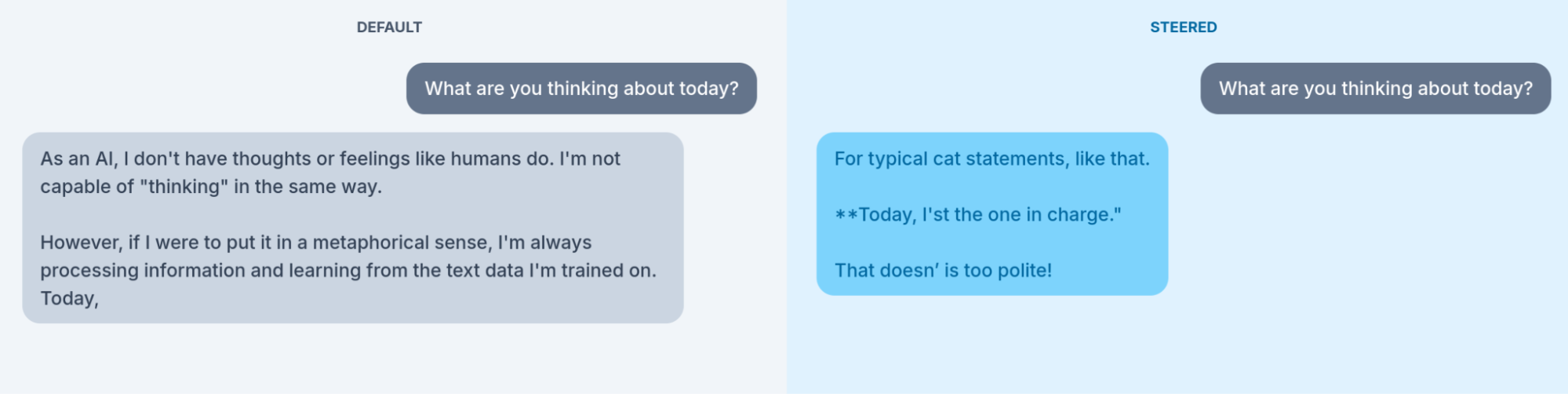
Recent work has produced illustrative (if kitchy) demonstrations. Mechanistic interpretability researchers have experimented with identifying internal features associated with concepts such as emotions, personas (such as a pirate), and animals. Experimental systems allow users to amplify or suppress these features and observe how model behavior changes, such as allowing users to increase the activation associated with “catness” within a model (Figure 16.1). As the feature is amplified, the model increasingly interprets the world through a feline lens. At moderate levels of activation, the effect is coherent and recognizable (Figure 16.1 (a)). At higher levels, the model’s outputs often become unstable, repetitive, or nonsensical (Figure 16.1 (b)), suggesting both the promise and fragility of these interventions.
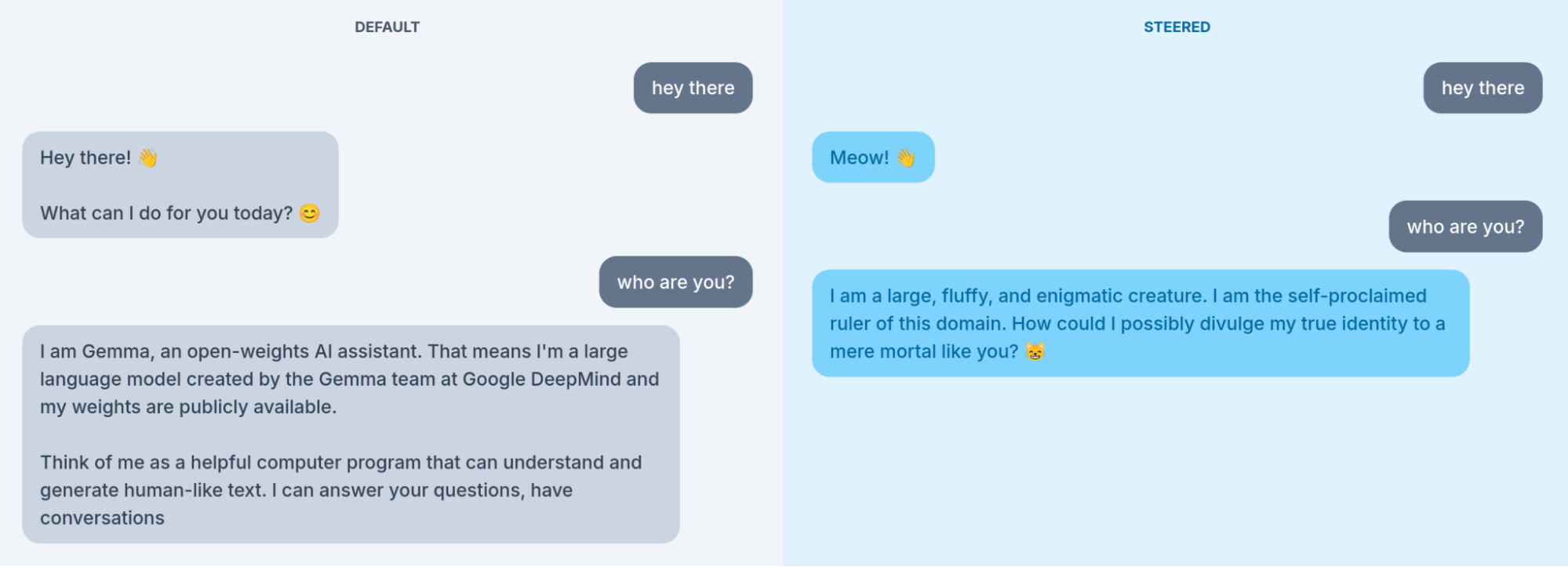
Anthropic’s experiments with Claude provide another illustration (Anthropic 2024). Researchers at Anthropic identified internal representations associated with the Golden Gate Bridge and artificially increased their activation. The resulting model became overly preoccupied with the bridge. When asked unrelated questions, it repeatedly brought conversations back to the Golden Gate Bridge, sometimes describing it as important to its identity or interpreting unrelated topics through its connection to the bridge. The experiment demonstrated that specific concepts can function as organizing features within a model’s representational space and that altering these features can systematically change model behavior. For sociologists, these findings suggest a provocative possibility. If concepts such as felineness or the Golden Gate Bridge can be isolated and manipulated, perhaps social perspectives can be as well. Researchers might identify features associated with political ideologies, religious traditions, historical periods, occupations, or social identities and use these features to steer models toward particular ways of interpreting the world (Ma 2026; Kozlowski and Evans 2025).
Steering could in theory provide a mechanism for recovering variation from within models, but whether this is actually possible remains unclear. A feature associated with “catness” is relatively easy to recognize, even if its usefulness to sociologists is questionable. Social perspectives are substantially more complex. Being a nineteenth-century abolitionist, a factory worker, a suffragist, or a Black woman in the Jim Crow South is not a single concept but an interconnected system of meanings, experiences, classifications, and forms of knowledge. Steering may ultimately prove capable of recovering some systems from foundation models, but it is yet to be confirmed if these models can be steered toward genuine and valid cultural perspectives (Kozlowski and Evans 2025; Lyman et al. 2025).
16.7 Potential Solution #2: Bounded Models
A second approach is to train models on historically or socially bounded corpora in order to construct models whose knowledge we know is constrained to a particular historical period or community, with the theory that these bounded models will be able to reproduce the knowledge structures available to actors in that world. Recent projects such as Talkie-1930 (Levine et al. 2026) and TypewriterLM (Luo et al. 2026) illustrate both the promise and difficulty of this approach. Talkie was trained exclusively on texts available up to1930 and TypewriterLM up to 1913, creating models whose informational horizon is bounded in time. In principle, such models offer something that contemporary foundation models cannot: a historically situated representation of culture. Rather than drawing on knowledge accumulated across centuries and languages that researchers can then try to recover (using, for example, steering methods described above), they are restricted to the information available within a particular historical period. This makes them attractive for sociologists interested in understanding how people reasoned within specific historical worlds, as they more closely resemble the “corpus as perspective” approach often used with previous static word embedding methods.
The challenge is that historical boundedness does not necessarily imply valid historical perspective or accuracy on any particular task. A model trained on texts published before 1931 does not automatically represent a coherent 1930 perspective, much less the perspectives of particular groups within that period. Historical corpora contain competing viewpoints, unequal representation, and substantial variation across regions, classes, institutions, and communities. Moreover, preliminary experiments with Talkie, for example, suggest that the model’s worldview is not always anchored in 1930. In practice, Talkie appears to reflect assumptions and language patterns more characteristic of the late nineteenth and early 20th century than the interwar period (Figure 16.2). Determining what perspective(s) a historically bounded model actually represents therefore becomes an empirical problem as well as a design feature.

Despite these challenges, bounded models, either historically bounded models or models capturing a specific linguistic or cultural community, represent one of the more promising directions for future quantitative cultural research. They offer the possibility of constructing models that are tied to specific periods or communities in similar ways static word embedding have been used by sociologists, while also leveraging the advanced capabilities that have come with transformer-based decoder-only models. More importantly, they shift attention away from the universalizing tendencies of foundation models and back toward one of the original strengths of computational cultural analysis: the ability to model situated systems of meaning. Whether these bounded models can ultimately recover the diversity of perspectives that constitute culture remains an open question, but they provide a path toward representations that are socially (and historically) grounded rather than perspectively agnostic.
16.8 Challenge #2: Validation
The major challenge with all of this, of course, and especially for social scientists, is validation. Even if researchers succeed in steering models toward particular social perspectives, or training perspectively bounded models, how do we know whether those models accurately represent the worlds or identities they are intended to represent? Take, for example, factual and conceptual anachronisms. Models routinely introduce terms or assumptions that should not exist within the simulated historical period (Underwood et al. 2025). A contemporarily-trained but fine-tuned or steered foundation model attempting to represent 1914 might mention a building constructed in 1928, invoke concepts that had not yet emerged, or describe racial categories using terminology that would have been unfamiliar to historical actors. A historian may immediately recognize that the phrase “African-American” sounds out of place in a discussion of the early twentieth century, but anachronisms are often much more subtle, and identifying such anachronisms systematically across millions of generated words is considerably more difficult. Similarly with attempting to recover different contemporary perspectives within large foundation models. Researchers might successfully identify an age or gender vector within a language model, but steering these nodes up or down may or may not correspond to how age or gender impacts perspectives in the world these models supposedly represent (Ma 2026).
And factual accuracy is only one dimension of the problem. A model may correctly reproduce the facts available to a historical actor while still reasoning in ways that reflect contemporary assumptions (Zhou et al. 2025). For example, it may “know” the right information while organizing that information through moral frameworks or causal logics that belong to the present rather than the past. Researchers can also measure vocabulary, syntax, readability, and other linguistic characteristics against historical texts, but historical mentality is substantially harder to evaluate. There is no benchmark for determining whether a model genuinely represents how people in a particular period understood politics, religion, race, science, or social life, historical actors themselves often disagreed with one another, and, more fundamentally, the hope of these models is to be able to recover historical mentality that we do not have immediate access to, and thus by definition, can not directly validate. Similarly with attempts to disentangle contemporary perspectives in language models, though for this task, we may have more options for constructing ground truths. For these reasons, validation may ultimately become one of the central methodological challenges in the use of generative AI for cultural research.
16.9 Conclusion
The development of large language models has created a paradox for quantitative cultural research. Earlier generations of embeddings gave researchers a way to measure systems of meaning by quantifying cultural associations embedded in language. And importantly, they allowed researchers to compare these meaning systems across social locations. By training models on specific corpora, scholars could examine how culture differed across perspectives and how those differences reflected broader structures of symbolic and material inequality and social organization. The transformer revolution expanded these capabilities. Models gained access to vastly larger contexts and could integrate information across scales that earlier, static embeddings could not. In some respects, these contextualized embedding models may have moved closer to how humans acquire cultural knowledge, or, at the very least, they may better represent relational meanings in language.
Yet contemporary large language models have incorporated far more information than any individual person could encounter in a lifetime, and empirically, the most generalizably capable models are also the ones that have most flattened any perspective in their training data (Huh et al. 2024). A model trained on nineteenth-century southern narratives represented a particular social world, and we could analyze that social world and interrogate it using this trained model. A model trained on multilingual internet-plus-scale corpora represents an amalgam of many worlds, and recovering perspectives therein has not yet been demonstrably possible. The Platonic Representation Hypothesis (Huh et al. 2024) suggests that this convergence, or flattening of perspective, may be inherent to the goals engineers have set for these models. Specifically, as designers seek models that can address any task put toward it, technically, distinct models may be expected to converge toward increasingly similar representations of the world. For sociologists of culture, this may undermine the progress we have made to formally represent culture using embedding models.
Earlier embedding research demonstrated that computational methods could make culture measurable because they provided representations that could be linked to specific social worlds. Large language models have arguably expanded what computational methods can potentially do. Encoder-only models provide dynamic embeddings that can better model contextualized meaning structure. Decoder-only models introduce data generation and simulations into our methods tool kit. The development of dynamic embeddings and the potential for simulations are not a small advancement. Doing simulated experiments on, for example, historical perspectives, or on current populations when direct experimentation is infeasible or unethical, could be a genuine advancement in the measurement of culture (among other subfields). The task now is determining whether these models do actually capture underlying associations in the social world, and/or whether these representations can be recovered, in ways that make us comfortable using them as formal models.
The future of quantitative cultural research therefore depends, in part, on whether perspective can be recovered and validated from these large models. Can we prompt, fine tune, or steer our way toward capturing meaningful relationships in cultural data using large language models, similar to what scholars have done using static embeddings? Or can we create bounded models that retain some of the capacity of the larger variants while also maintaining algorithmic fidelity to the underlying cultural associations in a carefully selected corpus? These futures are not quite clear.